找到
22
篇与
教程
相关的结果
- 第 2 页
-
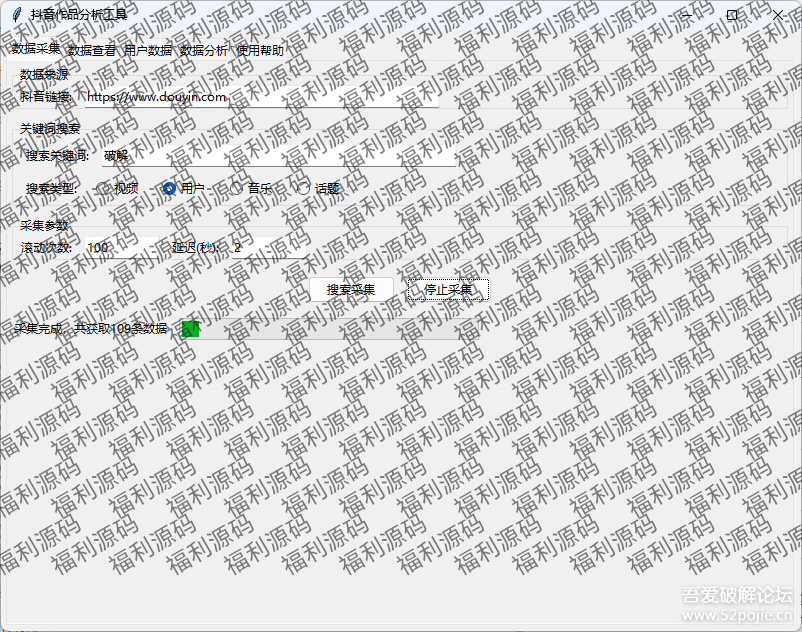
 抖音数据采集分析工具 Python 源码免费下载 - 深度洞察抖音数据的利器 抖音数据采集分析工具Python源码免费大放送,开启数据洞察新征程 在当今数字化浪潮席卷全球的时代,数据已然成为各行各业发展的核心驱动力。尤其是在短视频领域,抖音作为行业的佼佼者,蕴含着海量的数据宝藏。为了帮助广大用户能够更加便捷、高效地挖掘这些数据背后的价值,我们怀着激动的心情向大家宣布——抖音作品数据采集分析工具的Python源码正式对外开放,而且完全免费! 这款精心打造的工具,堪称内容创作者与市场分析师的“得力神兵”。对于内容创作者来说,通过对抖音作品数据的深入分析,能够精准洞察观众的喜好与需求,从而创作出更贴合市场、更具吸引力的优质内容,提升自身在抖音平台的影响力与竞争力。对于市场分析师而言,该工具采集的丰富数据,能够为市场趋势研究、竞品分析等提供坚实的数据支撑,帮助企业制定更加科学、有效的市场策略。 截图 使用截图图片 一、技术细节与使用要点 (一)代码编写与调试 本工具的代码是基于cursor编写而成,这一技术架构为工具的数据采集与分析功能奠定了坚实的基础。然而,就像任何一款处于不断优化过程中的软件产品一样,目前代码存在部分报错情况,并且个别模块尚未调试完善。但这并非是阻碍,而是为广大技术爱好者提供了一个施展才华的舞台。对于那些拥有扎实技术功底、热衷于探索与创新的用户而言,这无疑是一次难得的机会。你可以深入到代码的世界中,通过自己的智慧和努力,对这些问题进行调试与优化,不仅能够让工具更加符合自己的使用需求,还能在这个过程中提升自己的编程技能。 (二)配置要求 在使用该工具之前,有一个关键的准备步骤,那就是用户需要自行配置谷歌浏览器驱动。谷歌浏览器驱动在工具的数据采集过程中起着至关重要的桥梁作用,它能够确保工具与浏览器之间的通信顺畅,从而实现高效的数据采集。虽然这一配置过程可能需要花费一些时间和精力,但当你成功完成配置,看到工具顺利运行并为你采集到所需的数据时,一切的付出都将得到丰厚的回报。 二、使用便捷性:代码获取方式 为了最大程度地方便大家获取,我们将代码精心保存为文件,并提供了云盘下载渠道。这种方式不仅确保了代码的完整性,还让用户能够轻松快捷地将代码下载到本地,随时开始自己的数据采集与分析之旅。 当然你也可以复制粘贴↓ #您下载的资源来着www.fulicode.cn import tkinter as tk from tkinter import ttk, messagebox from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time import threading import pandas as pd import json from datetime import datetime import os from urllib.parse import quote from bs4 import BeautifulSoup import jieba from collections import Counter import traceback class DouyinAnalyzer: def __init__(self, root): self.root = root self.root.title("抖音作品分析工具") self.root.geometry("800x600") # 创建变量 self.url = tk.StringVar(value="https://www.douyin.com") self.scroll_count = tk.StringVar(value="100") self.delay = tk.StringVar(value="2") self.is_running = False self.collected_data = [] # 创建界面 self.create_widgets() def create_widgets(self): # 创建notebook用于标签页 self.notebook = ttk.Notebook(self.root) self.notebook.pack(fill='both', expand=True, padx=5, pady=5) # 创建各个标签页 self.create_collection_tab() self.create_data_tab() self.create_user_data_tab() self.create_analysis_tab() self.create_help_tab() # 添加帮助标签页 def create_collection_tab(self): """创建数据采集标签页""" collection_frame = ttk.Frame(self.notebook) self.notebook.add(collection_frame, text='数据采集') # URL输入框 url_frame = ttk.LabelFrame(collection_frame, text='数据来源') url_frame.pack(fill='x', padx=5, pady=5) ttk.Label(url_frame, text="抖音链接:").pack(side='left', padx=5) ttk.Entry(url_frame, textvariable=self.url, width=50).pack(side='left', padx=5) # 添加搜索框架 search_frame = ttk.LabelFrame(collection_frame, text='关键词搜索') search_frame.pack(fill='x', padx=5, pady=5) # 搜索关键词输入 keyword_frame = ttk.Frame(search_frame) keyword_frame.pack(fill='x', padx=5, pady=5) ttk.Label(keyword_frame, text="搜索关键词:").pack(side='left', padx=5) self.search_keyword = tk.StringVar() ttk.Entry(keyword_frame, textvariable=self.search_keyword, width=50).pack(side='left', padx=5) # 搜索类型选择(单选框) type_frame = ttk.Frame(search_frame) type_frame.pack(fill='x', padx=5, pady=5) ttk.Label(type_frame, text="搜索类型:").pack(side='left', padx=5) self.search_type = tk.StringVar(value='video') search_types = [ ('视频', 'video'), ('用户', 'user'), ('音乐', 'music'), ('话题', 'hashtag') ] # 创建单选框 for text, value in search_types: ttk.Radiobutton( type_frame, text=text, value=value, variable=self.search_type ).pack(side='left', padx=10) # 参数设置框 param_frame = ttk.LabelFrame(collection_frame, text='采集参数') param_frame.pack(fill='x', padx=5, pady=5) ttk.Label(param_frame, text="滚动次数:").pack(side='left', padx=5) ttk.Entry(param_frame, textvariable=self.scroll_count, width=10).pack(side='left', padx=5) ttk.Label(param_frame, text="延迟(秒):").pack(side='left', padx=5) ttk.Entry(param_frame, textvariable=self.delay, width=10).pack(side='left', padx=5) # 按钮框 button_frame = ttk.Frame(collection_frame) button_frame.pack(pady=10) ttk.Button(button_frame, text="搜索采集", command=self.start_search_collection).pack(side='left', padx=5) ttk.Button(button_frame, text="停止采集", command=self.stop_collection).pack(side='left', padx=5) # 状态栏 status_frame = ttk.Frame(collection_frame) status_frame.pack(fill='x', pady=5) self.status_label = ttk.Label(status_frame, text="就绪") self.status_label.pack(side='left', padx=5) self.progress = ttk.Progressbar(status_frame, length=300, mode='determinate') self.progress.pack(side='left', padx=5) def create_data_tab(self): """创建数据查看标签页""" data_frame = ttk.Frame(self.notebook) self.notebook.add(data_frame, text='数据查看') # 创建工具栏 toolbar = ttk.Frame(data_frame) toolbar.pack(fill='x', padx=5, pady=5) # 添加导出按钮 ttk.Button(toolbar, text="导出Excel", command=self.export_excel).pack(side='left', padx=5) ttk.Button(toolbar, text="导出JSON", command=self.export_json).pack(side='left', padx=5) # 添加统计标签 self.stats_label = ttk.Label(toolbar, text="共采集到 0 条数据") self.stats_label.pack(side='right', padx=5) # 创建表格 columns = ('序号', '标题', '作者', '发布时间', '点赞数', '视频链接') self.data_tree = ttk.Treeview(data_frame, columns=columns, show='headings') # 设置列标题和宽度 for col in columns: self.data_tree.heading(col, text=col, command=lambda c=col: self.treeview_sort_column(self.data_tree, c, False)) # 设置列宽 self.data_tree.column('序号', width=50) self.data_tree.column('标题', width=200) self.data_tree.column('作者', width=100) self.data_tree.column('发布时间', width=100) self.data_tree.column('点赞数', width=70) self.data_tree.column('视频链接', width=200) # 添加滚动条 scrollbar = ttk.Scrollbar(data_frame, orient='vertical', command=self.data_tree.yview) self.data_tree.configure(yscrollcommand=scrollbar.set) # 使用grid布局管理器 self.data_tree.pack(side='left', fill='both', expand=True) scrollbar.pack(side='right', fill='y') # 绑定双击事件 self.data_tree.bind('<Double-1>', self.on_tree_double_click) def create_user_data_tab(self): """创建用户数据查看标签页""" user_frame = ttk.Frame(self.notebook) self.notebook.add(user_frame, text='用户数据') # 创建工具栏 toolbar = ttk.Frame(user_frame) toolbar.pack(fill='x', padx=5, pady=5) # 添加导出按钮 ttk.Button(toolbar, text="导出Excel", command=self.export_user_excel).pack(side='left', padx=5) ttk.Button(toolbar, text="导出JSON", command=self.export_user_json).pack(side='left', padx=5) # 添加统计标签 self.user_stats_label = ttk.Label(toolbar, text="共采集到 0 位用户") self.user_stats_label.pack(side='right', padx=5) # 创建表格 columns = ('序号', '用户名', '抖音号', '获赞数', '粉丝数', '简介', '主页链接', '头像链接') self.user_tree = ttk.Treeview(user_frame, columns=columns, show='headings') # 设置列标题和排序功能 for col in columns: self.user_tree.heading(col, text=col, command=lambda c=col: self.treeview_sort_column(self.user_tree, c, False)) # 设置列宽 self.user_tree.column('序号', width=50) self.user_tree.column('用户名', width=150) self.user_tree.column('抖音号', width=100) self.user_tree.column('获赞数', width=70) self.user_tree.column('粉丝数', width=70) self.user_tree.column('简介', width=200) self.user_tree.column('主页链接', width=150) self.user_tree.column('头像链接', width=150) # 添加滚动条 scrollbar = ttk.Scrollbar(user_frame, orient='vertical', command=self.user_tree.yview) self.user_tree.configure(yscrollcommand=scrollbar.set) # 布局 self.user_tree.pack(side='left', fill='both', expand=True) scrollbar.pack(side='right', fill='y') # 绑定双击事件 self.user_tree.bind('<Double-1>', self.on_user_tree_double_click) def on_tree_double_click(self, event): """处理表格双击事件""" try: item = self.data_tree.selection()[0] values = self.data_tree.item(item)['values'] if not values: return video_url = values[5] # 获取视频链接 if video_url: # 确保URL格式正确 if not video_url.startswith('http'): if video_url.startswith('//'): video_url = 'https:' + video_url elif video_url.startswith('/'): video_url = 'https://www.douyin.com' + video_url else: video_url = 'https://www.douyin.com/' + video_url # 使用默认浏览器打开链接 import webbrowser webbrowser.open(video_url) except Exception as e: print(f"打开视频链接错误: {str(e)}") messagebox.showerror("错误", "无法打开视频链接") def on_user_tree_double_click(self, event): """处理用户表格双击事件""" try: item = self.user_tree.selection()[0] values = self.user_tree.item(item)['values'] if not values: return user_url = values[6] # 获取用户主页链接 if user_url: # 确保URL格式正确 if not user_url.startswith('http'): if user_url.startswith('//'): user_url = 'https:' + user_url elif user_url.startswith('/'): user_url = 'https://www.douyin.com' + user_url else: user_url = 'https://www.douyin.com/' + user_url # 使用默认浏览器打开链接 import webbrowser webbrowser.open(user_url) except Exception as e: print(f"打开用户主页链接错误: {str(e)}") messagebox.showerror("错误", "无法打开用户主页链接") def create_analysis_tab(self): """创建数据分析标签页""" analysis_frame = ttk.Frame(self.notebook) self.notebook.add(analysis_frame, text='数据分析') # 创建分析结果文本框 self.analysis_text = tk.Text(analysis_frame, height=20, width=60) self.analysis_text.pack(pady=10, padx=10, fill='both', expand=True) # 创建按钮框架 button_frame = ttk.Frame(analysis_frame) button_frame.pack(pady=5) # 添加分析按钮 ttk.Button(button_frame, text="互动数据分析", command=self.analyze_interaction_data).pack(side='left', padx=5) ttk.Button(button_frame, text="内容长度分析", command=self.analyze_content_length).pack(side='left', padx=5) ttk.Button(button_frame, text="高频词汇分析", command=self.analyze_keywords).pack(side='left', padx=5) ttk.Button(button_frame, text="清空分析结果", command=lambda: self.analysis_text.delete(1.0, tk.END)).pack(side='left', padx=5) def start_search_collection(self): """开始搜索采集""" if self.is_running: messagebox.showwarning("警告", "采集正在进行中!") return self.is_running = True threading.Thread(target=self.scroll_and_collect_search).start() def scroll_and_collect_search(self): """滚动页面并收集搜索结果数据""" driver = None try: # 配置Chrome选项 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-dev-shm-usage') chrome_options.add_argument('--disable-extensions') chrome_options.add_argument('--disable-logging') chrome_options.add_argument('--log-level=3') # 启动浏览器 driver = webdriver.Chrome(options=chrome_options) # 构建搜索URL keyword = self.search_keyword.get().strip() if not keyword: messagebox.showwarning("警告", "请输入搜索关键词!") return search_type = self.search_type.get() search_url = f"https://www.douyin.com/search/{quote(keyword)}?source=normal_search&type={search_type}" print(f"访问搜索URL: {search_url}") # 访问页面 driver.get(search_url) driver.maximize_window() # 等待页面加载 try: if search_type == 'user': # 等待用户列表加载 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, '#search-content-area')) ) # 额外等待确保内容完全加载 time.sleep(5) # 增加等待时间 else: # 等待视频列表加载 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, 'li.SwZLHMKk')) ) except Exception as e: print(f"等待页面加载超时: {str(e)}") time.sleep(3) # 额外等待时间 # 获取滚动次数和延迟 scroll_times = int(self.scroll_count.get()) delay = float(self.delay.get()) # 开始滚动和采集 last_height = driver.execute_script("return document.body.scrollHeight") for i in range(scroll_times): if not self.is_running: break try: # 滚动页面 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(delay) # 检查是否到达底部 new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: print("已到达页面底部") break last_height = new_height # 获取页面源码并解析 page_source = driver.page_source soup = BeautifulSoup(page_source, 'html.parser') # 根据搜索类型选择不同的提取方法 if search_type == 'user': new_data = self.extract_user_data(soup) else: container = soup.select_one('[data-e2e="scroll-list"]') if container: new_data = self.extract_video_items(container) else: print("未找到视频列表容器") continue print(f"本次滚动找到 {len(new_data)} 条新数据") # 添加新数据(去重) for data in new_data: if data not in self.collected_data: self.collected_data.append(data) print(f"当前总共采集 {len(self.collected_data)} 条数据") # 更新数据显示 self.root.after(0, self.update_data_display) # 使用after确保在主线程中更新UI # 更新状态 self.status_label.config(text=f"正在滚动... ({i+1}/{scroll_times})") self.progress['value'] = (i + 1) / scroll_times * 100 except Exception as e: print(f"滚动错误: {str(e)}") continue print("搜索结果采集完成") self.status_label.config(text=f"采集完成,共获取{len(self.collected_data)}条数据") except Exception as e: print(f"搜索采集过程出错: {str(e)}") messagebox.showerror("错误", f"采集过程出错: {str(e)}") finally: self.is_running = False if driver: driver.quit() def extract_video_data(self, html): """提取数据""" if self.search_type.get() == 'user': return self.extract_user_data(html) else: return self.extract_video_items(html) def extract_user_data(self, html): """提取用户数据""" print("开始提取用户数据...") # 使用正确的选择器定位用户列表 user_items = html.select("div.search-result-card > a.hY8lWHgA.poLTDMYS") # 更新选择器 print(f"找到 {len(user_items)} 个用户项") user_data = [] for item in user_items: try: # 获取用户链接 user_link = item.get('href', '') # 获取标题 title_elem = item.select_one('div.XQwChAbX p.v9LWb7QE span span span span span') title = title_elem.get_text(strip=True) if title_elem else '' # 获取头像URL avatar_elem = item.select_one('img.RlLOO79h') avatar_url = avatar_elem.get('src', '') if avatar_elem else '' # 获取统计数据 stats_div = item.select_one('div.jjebLXt0') douyin_id = '' likes = '0' followers = '0' if stats_div: spans = stats_div.select('span') for span in spans: text = span.get_text(strip=True) print(f"处理span文本: {text}") # 调试输出 if '抖音号:' in text or '抖音号:' in text: id_span = span.select_one('span') if id_span: douyin_id = id_span.get_text(strip=True) elif '获赞' in text: likes = text.replace('获赞', '').strip() elif '粉丝' in text: followers = text.replace('粉丝', '').strip() # 获取简介 desc_elem = item.select_one('p.Kdb5Km3i span span span span span') description = desc_elem.get_text(strip=True) if desc_elem else '' # 构建数据 data = { 'title': title, 'douyin_id': douyin_id, 'likes': likes, 'followers': followers, 'description': description, 'avatar_url': avatar_url, 'user_link': user_link } # 清理数据 data = {k: self.clean_text(str(v)) for k, v in data.items()} # 格式化数字 data['likes'] = self.format_number(data['likes']) data['followers'] = self.format_number(data['followers']) # 处理用户链接 if data['user_link'] and not data['user_link'].startswith('http'): data['user_link'] = 'https://www.douyin.com' + data['user_link'] # 打印调试信息 print("\n提取到的数据:") for key, value in data.items(): print(f"{key}: {value}") # 只要有标题就添加 if data['title']: if data not in user_data: # 确保不重复添加 user_data.append(data) print(f"成功提取用户数据: {data['title']}") except Exception as e: print(f"提取单个用户数据错误: {str(e)}") traceback.print_exc() # 打印完整的错误堆栈 continue print(f"总共提取到 {len(user_data)} 条用户数据") return user_data def _extract_basic_info(self, item): """提取基本信息""" # 获取用户链接 user_link = item.select_one('a.uz1VJwFY') # 使用确切的类名 # 获取标题 title = "" title_elem = item.select_one('p.ZMZLqKYm span') # 使用确切的类名和结构 if title_elem: title = title_elem.get_text(strip=True) # 获取头像URL avatar_elem = item.select_one('img.fiWP27dC') avatar_url = avatar_elem.get('src', '') if avatar_elem else '' return { 'title': title, 'douyin_id': '', 'likes': '', 'followers': '', 'description': '', 'avatar_url': avatar_url, 'user_link': user_link.get('href', '') if user_link else '' } def _extract_stats_info(self, item, data): """提取统计信息""" stats_div = item.select_one('div.Y6iuJGlc') # 使用确切的类名 if stats_div: spans = stats_div.select('span') spans_text = [span.get_text(strip=True) for span in spans] print(f"找到的span文本: {spans_text}") # 调试输出 for text in spans_text: if '抖音号:' in text or '抖音号:' in text: # 获取嵌套的span中的抖音号 nested_span = stats_div.select_one('span > span') if nested_span: data['douyin_id'] = nested_span.get_text(strip=True) elif '获赞' in text: data['likes'] = text.replace('获赞', '').strip() elif '粉丝' in text: data['followers'] = text.replace('粉丝', '').strip() def _extract_description(self, item, data): """提取用户简介""" desc_elem = item.select_one('p.NYqiIDUo span') # 使用确切的类名和结构 if desc_elem: # 获取纯文本内容,去除表情图片 text_nodes = [node for node in desc_elem.stripped_strings] data['description'] = ' '.join(text_nodes) def _clean_and_format_data(self, data): """清理和格式化数据""" # 清理文本数据 for key in data: if isinstance(data[key], str): data[key] = self.clean_text(data[key]) # 格式化数字 data['likes'] = self.format_number(data['likes']) data['followers'] = self.format_number(data['followers']) # 处理用户链接 if data['user_link']: link = data['user_link'] # 移除查询参数 if '?' in link: link = link.split('?')[0] # 确保正确的格式 if link.startswith('//'): link = 'https:' + link elif not link.startswith('http'): # 移除可能的重复路径 link = link.replace('www.douyin.com/', '') link = link.replace('//', '/') if not link.startswith('/'): link = '/' + link link = 'https://www.douyin.com' + link print(f"原始链接: {data['user_link']}") # 调试输出 print(f"处理后链接: {link}") # 调试输出 data['user_link'] = link def _print_debug_info(self, data): """打印调试信息""" print("\n提取到的数据:") print(f"标题: {data['title']}") print(f"抖音号: {data['douyin_id']}") print(f"获赞: {data['likes']}") print(f"粉丝: {data['followers']}") print(f"简介: {data['description'][:50]}...") print(f"链接: {data['user_link']}") def extract_video_items(self, html): """提取视频数据(原有代码)""" video_items = html.select("li.SwZLHMKk") video_data = [] for item in video_items: try: # 获取视频链接 video_link = item.select_one('a.hY8lWHgA') if not video_link: continue # 构建数据 data = { 'video_url': video_link['href'].strip(), 'cover_image': item.select_one('img')['src'].strip() if item.select_one('img') else '', 'title': item.select_one('div.VDYK8Xd7').text.strip() if item.select_one('div.VDYK8Xd7') else '无标题', 'author': item.select_one('span.MZNczJmS').text.strip() if item.select_one('span.MZNczJmS') else '未知作者', 'publish_time': item.select_one('span.faDtinfi').text.strip() if item.select_one('span.faDtinfi') else '', 'likes': item.select_one('span.cIiU4Muu').text.strip() if item.select_one('span.cIiU4Muu') else '0' } # 清理数据 data = {k: self.clean_text(str(v)) for k, v in data.items()} # 验证数据完整性 if all(data.values()): video_data.append(data) else: print(f"跳过不完整数据: {data}") except Exception as e: print(f"提取单个视频数据错误: {str(e)}") continue return video_data def update_data_display(self): """更新数据显示""" try: search_type = self.search_type.get() print(f"更新数据显示,搜索类型: {search_type}") print(f"当前数据数量: {len(self.collected_data)}") if search_type == 'user': self.notebook.select(2) # 先切换到用户数据标签页 self.root.after(100, self.update_user_display) # 延迟一小段时间后更新显示 else: self.notebook.select(1) # 切换到视频数据标签页 self.root.after(100, self.update_video_display) except Exception as e: print(f"更新数据显示错误: {str(e)}") def update_user_display(self): """更新用户数据显示""" try: # 清空现有显示 self.user_tree.delete(*self.user_tree.get_children()) # 添加新数据 for i, data in enumerate(self.collected_data): try: # 格式化简介 description = data.get('description', '') if len(description) > 50: description = description[:47] + '...' # 格式化数据 values = ( i + 1, data.get('title', ''), data.get('douyin_id', ''), self.format_number(str(data.get('likes', '0'))), self.format_number(str(data.get('followers', '0'))), description, data.get('user_link', ''), data.get('avatar_url', '') ) self.user_tree.insert('', 'end', values=values) print(f"显示用户数据: {data.get('title', '')}") except Exception as e: print(f"处理单条用户数据显示错误: {str(e)}") continue # 更新统计 self.user_stats_label.config(text=f"共采集到 {len(self.collected_data)} 位用户") print(f"更新用户统计: {len(self.collected_data)} 位用户") # 自动滚动到最新数据 if self.user_tree.get_children(): self.user_tree.see(self.user_tree.get_children()[-1]) except Exception as e: print(f"更新用户数据显示错误: {str(e)}") def update_video_display(self): """更新视频数据显示(原有的update_data_display逻辑)""" try: # 清空现有显示 self.data_tree.delete(*self.data_tree.get_children()) # 添加新数据 for i, data in enumerate(self.collected_data): try: title = data.get('title', '') if len(title) > 50: title = title[:47] + '...' values = ( i + 1, title, data.get('author', '未知作者'), data.get('publish_time', ''), self.format_number(str(data.get('likes', '0'))), data.get('video_url', '') ) self.data_tree.insert('', 'end', values=values) except Exception as e: print(f"处理单条数据显示错误: {str(e)}") continue # 更新统计 self.stats_label.config(text=f"共采集到 {len(self.collected_data)} 条数据") # 自动滚动到最新数据 if self.data_tree.get_children(): self.data_tree.see(self.data_tree.get_children()[-1]) except Exception as e: print(f"更新数据显示错误: {str(e)}") def update_data_stats(self): """更新数据统计""" try: total_count = len(self.collected_data) self.stats_label.config(text=f"共采集到 {total_count} 条数据") except Exception as e: print(f"更新统计信息错误: {str(e)}") def stop_collection(self): """停止数据采集""" if self.is_running: self.is_running = False self.status_label.config(text="已停止采集") print("采集已停止") else: print("当前没有正在进行的采集任务") def export_excel(self): """导出数据到Excel""" if not self.collected_data: messagebox.showwarning("警告", "没有数据可导出!") return try: filename = f"抖音数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx" df = pd.DataFrame(self.collected_data) df.to_excel(filename, index=False) messagebox.showinfo("成功", f"数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出Excel失败: {str(e)}") def export_json(self): """导出数据到JSON""" if not self.collected_data: messagebox.showwarning("警告", "没有数据可导出!") return try: filename = f"抖音数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump(self.collected_data, f, ensure_ascii=False, indent=2) messagebox.showinfo("成功", f"数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出JSON失败: {str(e)}") def export_user_excel(self): """导出用户数据到Excel""" if not self.collected_data or self.search_type.get() != 'user': messagebox.showwarning("警告", "没有用户数据可导出!") return try: filename = f"抖音用户数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx" df = pd.DataFrame(self.collected_data) df.to_excel(filename, index=False) messagebox.showinfo("成功", f"用户数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出Excel失败: {str(e)}") def export_user_json(self): """导出用户数据到JSON""" if not self.collected_data or self.search_type.get() != 'user': messagebox.showwarning("警告", "没有用户数据可导出!") return try: filename = f"抖音用户数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump(self.collected_data, f, ensure_ascii=False, indent=2) messagebox.showinfo("成功", f"用户数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出JSON失败: {str(e)}") def clean_text(self, text): """清理文本""" return text.replace('\n', ' ').replace('\r', '').strip() def format_number(self, num_str): """格式化数字字符串""" try: num = int(num_str) if num >= 10000: return f"{num / 10000:.1f}万" return str(num) except ValueError: return num_str def analyze_interaction_data(self): """分析互动数据""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 将点赞数转换为数字 likes_data = [] for data in self.collected_data: likes = str(data['likes']) try: if '万' in likes: # 处理带"万"的数字 num = float(likes.replace('万', '')) * 10000 likes_data.append(int(num)) else: # 处理普通数字 likes_data.append(int(likes)) except (ValueError, TypeError): print(f"无法解析的点赞数: {likes}") continue # 计算统计数据 total_likes = sum(likes_data) avg_likes = total_likes / len(likes_data) if likes_data else 0 max_likes = max(likes_data) if likes_data else 0 # 生成报告 report = "===== 互动数据分析报告 =====\n\n" report += f"总视频数: {len(self.collected_data)}\n" report += f"总点赞数: {self.format_large_number(total_likes)}\n" report += f"平均点赞数: {self.format_large_number(int(avg_likes))}\n" report += f"最高点赞数: {self.format_large_number(max_likes)}\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: print(f"互动数据分析错误: {str(e)}") messagebox.showerror("错误", f"分析失败: {str(e)}") def format_large_number(self, num): """格式化大数字显示""" if num >= 10000: return f"{num/10000:.1f}万" return str(num) def analyze_content_length(self): """分析内容长度""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 计算标题长度 title_lengths = [len(data['title']) for data in self.collected_data] # 计算统计数据 avg_length = sum(title_lengths) / len(title_lengths) max_length = max(title_lengths) min_length = min(title_lengths) # 生成报告 report = "===== 内容长度分析报告 =====\n\n" report += f"平均标题长度: {avg_length:.1f}字\n" report += f"最长标题: {max_length}字\n" report += f"最短标题: {min_length}字\n\n" # 添加长度分布统计 length_ranges = [(0, 10), (11, 20), (21, 30), (31, 50), (51, 100), (101, float('inf'))] report += "标题长度分布:\n" for start, end in length_ranges: count = sum(1 for length in title_lengths if start <= length <= end) range_text = f"{start}-{end}字" if end != float('inf') else f"{start}字以上" percentage = (count / len(title_lengths)) * 100 report += f"{range_text}: {count}个 ({percentage:.1f}%)\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: messagebox.showerror("错误", f"分析失败: {str(e)}") def analyze_keywords(self): """分析标题中的高频词汇""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 合并所有标题文本 all_titles = ' '.join(data['title'] for data in self.collected_data) # 设置停用词 stop_words = { '的', '了', '是', '在', '我', '有', '和', '就', '都', '而', '及', '与', '着', '或', '等', '为', '一个', '没有', '这个', '那个', '但是', '而且', '只是', '不过', '这样', '一样', '一直', '一些', '这', '那', '也', '你', '我们', '他们', '它们', '把', '被', '让', '向', '往', '但', '去', '又', '能', '好', '给', '到', '看', '想', '要', '会', '多', '能', '这些', '那些', '什么', '怎么', '如何', '为什么', '可以', '因为', '所以', '应该', '可能', '应该' } # 使用jieba进行分词 words = [] for word in jieba.cut(all_titles): if len(word) > 1 and word not in stop_words: # 过滤单字词和停用词 words.append(word) # 统计词频 word_counts = Counter(words) # 生成报告 report = "===== 高频词汇分析报告 =====\n\n" report += f"总标题数: {len(self.collected_data)}\n" report += f"总词汇量: {len(words)}\n" report += f"不同词汇数: {len(word_counts)}\n\n" # 显示高频词汇(TOP 100) report += "高频词汇 TOP 100:\n" report += "-" * 40 + "\n" report += "排名\t词汇\t\t出现次数\t频率\n" report += "-" * 40 + "\n" for rank, (word, count) in enumerate(word_counts.most_common(100), 1): frequency = (count / len(words)) * 100 report += f"{rank}\t{word}\t\t{count}\t\t{frequency:.2f}%\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: print(f"高频词汇分析错误: {str(e)}") messagebox.showerror("错误", f"分析失败: {str(e)}") def treeview_sort_column(self, tree, col, reverse): """列排序函数""" # 获取所有项目 l = [(tree.set(k, col), k) for k in tree.get_children('')] try: # 尝试将数值型数据转换为数字进行排序 if col in ['序号', '获赞数', '粉丝数', '点赞数']: # 处理带"万"的数字 def convert_number(x): try: if '万' in x[0]: return float(x[0].replace('万', '')) * 10000 return float(x[0]) except ValueError: return 0 l.sort(key=convert_number, reverse=reverse) else: # 字符串排序 l.sort(reverse=reverse) except Exception as e: print(f"排序错误: {str(e)}") # 如果转换失败,按字符串排序 l.sort(reverse=reverse) # 重新排列项目 for index, (val, k) in enumerate(l): tree.move(k, '', index) # 更新序号 tree.set(k, '序号', str(index + 1)) # 切换排序方向 tree.heading(col, command=lambda: self.treeview_sort_column(tree, col, not reverse)) def create_help_tab(self): """创建帮助标签页""" help_frame = ttk.Frame(self.notebook) self.notebook.add(help_frame, text='使用帮助') # 创建帮助文本框 help_text = tk.Text(help_frame, wrap=tk.WORD, padx=10, pady=10) help_text.pack(fill='both', expand=True) # 添加滚动条 scrollbar = ttk.Scrollbar(help_frame, orient='vertical', command=help_text.yview) scrollbar.pack(side='right', fill='y') help_text.configure(yscrollcommand=scrollbar.set) # 帮助内容 help_content = """ 抖音作品分析工具使用指南 ==================== 1. 数据采集 ----------------- • 支持两种采集方式: - 直接输入抖音链接 - 关键词搜索采集 • 关键词搜索支持以下类型: - 视频搜索 - 用户搜索 - 音乐搜索 - 话题搜索 • 采集参数说明: - 滚动次数:决定采集数据量的多少 - 延迟(秒):每次滚动的等待时间,建议2-3秒 • 使用技巧: - 采集时可随时点击"停止采集" - 建议设置适当的延迟避免被限制 - 数据采集过程中请勿关闭浏览器窗口 2. 数据查看 ----------------- • 视频数据: - 包含标题、作者、发布时间等信息 - 双击可直接打开视频链接 - 支持按列排序 - 可导出为Excel或JSON格式 • 用户数据: - 显示用户名、抖音号、粉丝数等信息 - 双击可打开用户主页 - 支持数据排序 - 可单独导出用户数据 3. 数据分析 ----------------- • 互动数据分析: - 统计总点赞数、平均点赞等指标 - 展示互动数据分布情况 • 内容长度分析: - 分析标题长度分布 - 显示最长/最短标题统计 • 高频词汇分析: - 提取标题中的关键词 - 展示TOP100高频词汇 - 计算词频占比 4. 常见问题 ----------------- Q: 为什么采集速度较慢? A: 为了避免被反爬虫机制拦截,程序设置了延迟机制。 Q: 如何提高采集成功率? A: 建议: - 设置适当的延迟时间(2-3秒) - 避免过于频繁的采集 - 确保网络连接稳定 Q: 数据导出格式说明? A: 支持两种格式: - Excel格式:适合数据分析和处理 - JSON格式:适合数据备份和程序读取 Q: 如何处理采集失败? A: 可以: - 检查网络连接 - 增加延迟时间 - 减少单次采集数量 - 更换搜索关键词 5. 注意事项 ----------------- • 合理使用: - 遵守抖音平台规则 - 避免频繁、大量采集 - 合理设置采集参数 • 数据安全: - 及时导出重要数据 - 定期备份采集结果 • 使用建议: - 建议使用稳定的网络连接 - 采集时避免其他浏览器操作 - 定期清理浏览器缓存 如需更多帮助,请参考项目文档或联系开发者。 """ # 插入帮助内容 help_text.insert('1.0', help_content) help_text.config(state='disabled') # 设置为只读 if __name__ == "__main__": root = tk.Tk() app = DouyinAnalyzer(root) root.mainloop() #您下载的资源来自www.fulicode.cn三、下载指南 123云盘下载 抖音数据采集分析工具.zip 下载地址:https://www.123684.com/s/rCKrjv-Vpb8d? 提取码:vq7x无论你是经验丰富的专业开发者,能够熟练地对代码进行二次开发与定制;还是对抖音数据满怀热忱、刚刚踏入数据领域的爱好者,渴望通过数据了解抖音世界的奥秘,都能毫无门槛地获取这份宝贵的资源。我们衷心希望这款工具能够在你的创作与分析旅程中发挥重要作用,帮助你在抖音平台的创作之路上更加得心应手,在市场分析领域取得更优异的成果,开启属于自己的数据洞察新征程。
抖音数据采集分析工具 Python 源码免费下载 - 深度洞察抖音数据的利器 抖音数据采集分析工具Python源码免费大放送,开启数据洞察新征程 在当今数字化浪潮席卷全球的时代,数据已然成为各行各业发展的核心驱动力。尤其是在短视频领域,抖音作为行业的佼佼者,蕴含着海量的数据宝藏。为了帮助广大用户能够更加便捷、高效地挖掘这些数据背后的价值,我们怀着激动的心情向大家宣布——抖音作品数据采集分析工具的Python源码正式对外开放,而且完全免费! 这款精心打造的工具,堪称内容创作者与市场分析师的“得力神兵”。对于内容创作者来说,通过对抖音作品数据的深入分析,能够精准洞察观众的喜好与需求,从而创作出更贴合市场、更具吸引力的优质内容,提升自身在抖音平台的影响力与竞争力。对于市场分析师而言,该工具采集的丰富数据,能够为市场趋势研究、竞品分析等提供坚实的数据支撑,帮助企业制定更加科学、有效的市场策略。 截图 使用截图图片 一、技术细节与使用要点 (一)代码编写与调试 本工具的代码是基于cursor编写而成,这一技术架构为工具的数据采集与分析功能奠定了坚实的基础。然而,就像任何一款处于不断优化过程中的软件产品一样,目前代码存在部分报错情况,并且个别模块尚未调试完善。但这并非是阻碍,而是为广大技术爱好者提供了一个施展才华的舞台。对于那些拥有扎实技术功底、热衷于探索与创新的用户而言,这无疑是一次难得的机会。你可以深入到代码的世界中,通过自己的智慧和努力,对这些问题进行调试与优化,不仅能够让工具更加符合自己的使用需求,还能在这个过程中提升自己的编程技能。 (二)配置要求 在使用该工具之前,有一个关键的准备步骤,那就是用户需要自行配置谷歌浏览器驱动。谷歌浏览器驱动在工具的数据采集过程中起着至关重要的桥梁作用,它能够确保工具与浏览器之间的通信顺畅,从而实现高效的数据采集。虽然这一配置过程可能需要花费一些时间和精力,但当你成功完成配置,看到工具顺利运行并为你采集到所需的数据时,一切的付出都将得到丰厚的回报。 二、使用便捷性:代码获取方式 为了最大程度地方便大家获取,我们将代码精心保存为文件,并提供了云盘下载渠道。这种方式不仅确保了代码的完整性,还让用户能够轻松快捷地将代码下载到本地,随时开始自己的数据采集与分析之旅。 当然你也可以复制粘贴↓ #您下载的资源来着www.fulicode.cn import tkinter as tk from tkinter import ttk, messagebox from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time import threading import pandas as pd import json from datetime import datetime import os from urllib.parse import quote from bs4 import BeautifulSoup import jieba from collections import Counter import traceback class DouyinAnalyzer: def __init__(self, root): self.root = root self.root.title("抖音作品分析工具") self.root.geometry("800x600") # 创建变量 self.url = tk.StringVar(value="https://www.douyin.com") self.scroll_count = tk.StringVar(value="100") self.delay = tk.StringVar(value="2") self.is_running = False self.collected_data = [] # 创建界面 self.create_widgets() def create_widgets(self): # 创建notebook用于标签页 self.notebook = ttk.Notebook(self.root) self.notebook.pack(fill='both', expand=True, padx=5, pady=5) # 创建各个标签页 self.create_collection_tab() self.create_data_tab() self.create_user_data_tab() self.create_analysis_tab() self.create_help_tab() # 添加帮助标签页 def create_collection_tab(self): """创建数据采集标签页""" collection_frame = ttk.Frame(self.notebook) self.notebook.add(collection_frame, text='数据采集') # URL输入框 url_frame = ttk.LabelFrame(collection_frame, text='数据来源') url_frame.pack(fill='x', padx=5, pady=5) ttk.Label(url_frame, text="抖音链接:").pack(side='left', padx=5) ttk.Entry(url_frame, textvariable=self.url, width=50).pack(side='left', padx=5) # 添加搜索框架 search_frame = ttk.LabelFrame(collection_frame, text='关键词搜索') search_frame.pack(fill='x', padx=5, pady=5) # 搜索关键词输入 keyword_frame = ttk.Frame(search_frame) keyword_frame.pack(fill='x', padx=5, pady=5) ttk.Label(keyword_frame, text="搜索关键词:").pack(side='left', padx=5) self.search_keyword = tk.StringVar() ttk.Entry(keyword_frame, textvariable=self.search_keyword, width=50).pack(side='left', padx=5) # 搜索类型选择(单选框) type_frame = ttk.Frame(search_frame) type_frame.pack(fill='x', padx=5, pady=5) ttk.Label(type_frame, text="搜索类型:").pack(side='left', padx=5) self.search_type = tk.StringVar(value='video') search_types = [ ('视频', 'video'), ('用户', 'user'), ('音乐', 'music'), ('话题', 'hashtag') ] # 创建单选框 for text, value in search_types: ttk.Radiobutton( type_frame, text=text, value=value, variable=self.search_type ).pack(side='left', padx=10) # 参数设置框 param_frame = ttk.LabelFrame(collection_frame, text='采集参数') param_frame.pack(fill='x', padx=5, pady=5) ttk.Label(param_frame, text="滚动次数:").pack(side='left', padx=5) ttk.Entry(param_frame, textvariable=self.scroll_count, width=10).pack(side='left', padx=5) ttk.Label(param_frame, text="延迟(秒):").pack(side='left', padx=5) ttk.Entry(param_frame, textvariable=self.delay, width=10).pack(side='left', padx=5) # 按钮框 button_frame = ttk.Frame(collection_frame) button_frame.pack(pady=10) ttk.Button(button_frame, text="搜索采集", command=self.start_search_collection).pack(side='left', padx=5) ttk.Button(button_frame, text="停止采集", command=self.stop_collection).pack(side='left', padx=5) # 状态栏 status_frame = ttk.Frame(collection_frame) status_frame.pack(fill='x', pady=5) self.status_label = ttk.Label(status_frame, text="就绪") self.status_label.pack(side='left', padx=5) self.progress = ttk.Progressbar(status_frame, length=300, mode='determinate') self.progress.pack(side='left', padx=5) def create_data_tab(self): """创建数据查看标签页""" data_frame = ttk.Frame(self.notebook) self.notebook.add(data_frame, text='数据查看') # 创建工具栏 toolbar = ttk.Frame(data_frame) toolbar.pack(fill='x', padx=5, pady=5) # 添加导出按钮 ttk.Button(toolbar, text="导出Excel", command=self.export_excel).pack(side='left', padx=5) ttk.Button(toolbar, text="导出JSON", command=self.export_json).pack(side='left', padx=5) # 添加统计标签 self.stats_label = ttk.Label(toolbar, text="共采集到 0 条数据") self.stats_label.pack(side='right', padx=5) # 创建表格 columns = ('序号', '标题', '作者', '发布时间', '点赞数', '视频链接') self.data_tree = ttk.Treeview(data_frame, columns=columns, show='headings') # 设置列标题和宽度 for col in columns: self.data_tree.heading(col, text=col, command=lambda c=col: self.treeview_sort_column(self.data_tree, c, False)) # 设置列宽 self.data_tree.column('序号', width=50) self.data_tree.column('标题', width=200) self.data_tree.column('作者', width=100) self.data_tree.column('发布时间', width=100) self.data_tree.column('点赞数', width=70) self.data_tree.column('视频链接', width=200) # 添加滚动条 scrollbar = ttk.Scrollbar(data_frame, orient='vertical', command=self.data_tree.yview) self.data_tree.configure(yscrollcommand=scrollbar.set) # 使用grid布局管理器 self.data_tree.pack(side='left', fill='both', expand=True) scrollbar.pack(side='right', fill='y') # 绑定双击事件 self.data_tree.bind('<Double-1>', self.on_tree_double_click) def create_user_data_tab(self): """创建用户数据查看标签页""" user_frame = ttk.Frame(self.notebook) self.notebook.add(user_frame, text='用户数据') # 创建工具栏 toolbar = ttk.Frame(user_frame) toolbar.pack(fill='x', padx=5, pady=5) # 添加导出按钮 ttk.Button(toolbar, text="导出Excel", command=self.export_user_excel).pack(side='left', padx=5) ttk.Button(toolbar, text="导出JSON", command=self.export_user_json).pack(side='left', padx=5) # 添加统计标签 self.user_stats_label = ttk.Label(toolbar, text="共采集到 0 位用户") self.user_stats_label.pack(side='right', padx=5) # 创建表格 columns = ('序号', '用户名', '抖音号', '获赞数', '粉丝数', '简介', '主页链接', '头像链接') self.user_tree = ttk.Treeview(user_frame, columns=columns, show='headings') # 设置列标题和排序功能 for col in columns: self.user_tree.heading(col, text=col, command=lambda c=col: self.treeview_sort_column(self.user_tree, c, False)) # 设置列宽 self.user_tree.column('序号', width=50) self.user_tree.column('用户名', width=150) self.user_tree.column('抖音号', width=100) self.user_tree.column('获赞数', width=70) self.user_tree.column('粉丝数', width=70) self.user_tree.column('简介', width=200) self.user_tree.column('主页链接', width=150) self.user_tree.column('头像链接', width=150) # 添加滚动条 scrollbar = ttk.Scrollbar(user_frame, orient='vertical', command=self.user_tree.yview) self.user_tree.configure(yscrollcommand=scrollbar.set) # 布局 self.user_tree.pack(side='left', fill='both', expand=True) scrollbar.pack(side='right', fill='y') # 绑定双击事件 self.user_tree.bind('<Double-1>', self.on_user_tree_double_click) def on_tree_double_click(self, event): """处理表格双击事件""" try: item = self.data_tree.selection()[0] values = self.data_tree.item(item)['values'] if not values: return video_url = values[5] # 获取视频链接 if video_url: # 确保URL格式正确 if not video_url.startswith('http'): if video_url.startswith('//'): video_url = 'https:' + video_url elif video_url.startswith('/'): video_url = 'https://www.douyin.com' + video_url else: video_url = 'https://www.douyin.com/' + video_url # 使用默认浏览器打开链接 import webbrowser webbrowser.open(video_url) except Exception as e: print(f"打开视频链接错误: {str(e)}") messagebox.showerror("错误", "无法打开视频链接") def on_user_tree_double_click(self, event): """处理用户表格双击事件""" try: item = self.user_tree.selection()[0] values = self.user_tree.item(item)['values'] if not values: return user_url = values[6] # 获取用户主页链接 if user_url: # 确保URL格式正确 if not user_url.startswith('http'): if user_url.startswith('//'): user_url = 'https:' + user_url elif user_url.startswith('/'): user_url = 'https://www.douyin.com' + user_url else: user_url = 'https://www.douyin.com/' + user_url # 使用默认浏览器打开链接 import webbrowser webbrowser.open(user_url) except Exception as e: print(f"打开用户主页链接错误: {str(e)}") messagebox.showerror("错误", "无法打开用户主页链接") def create_analysis_tab(self): """创建数据分析标签页""" analysis_frame = ttk.Frame(self.notebook) self.notebook.add(analysis_frame, text='数据分析') # 创建分析结果文本框 self.analysis_text = tk.Text(analysis_frame, height=20, width=60) self.analysis_text.pack(pady=10, padx=10, fill='both', expand=True) # 创建按钮框架 button_frame = ttk.Frame(analysis_frame) button_frame.pack(pady=5) # 添加分析按钮 ttk.Button(button_frame, text="互动数据分析", command=self.analyze_interaction_data).pack(side='left', padx=5) ttk.Button(button_frame, text="内容长度分析", command=self.analyze_content_length).pack(side='left', padx=5) ttk.Button(button_frame, text="高频词汇分析", command=self.analyze_keywords).pack(side='left', padx=5) ttk.Button(button_frame, text="清空分析结果", command=lambda: self.analysis_text.delete(1.0, tk.END)).pack(side='left', padx=5) def start_search_collection(self): """开始搜索采集""" if self.is_running: messagebox.showwarning("警告", "采集正在进行中!") return self.is_running = True threading.Thread(target=self.scroll_and_collect_search).start() def scroll_and_collect_search(self): """滚动页面并收集搜索结果数据""" driver = None try: # 配置Chrome选项 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-dev-shm-usage') chrome_options.add_argument('--disable-extensions') chrome_options.add_argument('--disable-logging') chrome_options.add_argument('--log-level=3') # 启动浏览器 driver = webdriver.Chrome(options=chrome_options) # 构建搜索URL keyword = self.search_keyword.get().strip() if not keyword: messagebox.showwarning("警告", "请输入搜索关键词!") return search_type = self.search_type.get() search_url = f"https://www.douyin.com/search/{quote(keyword)}?source=normal_search&type={search_type}" print(f"访问搜索URL: {search_url}") # 访问页面 driver.get(search_url) driver.maximize_window() # 等待页面加载 try: if search_type == 'user': # 等待用户列表加载 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, '#search-content-area')) ) # 额外等待确保内容完全加载 time.sleep(5) # 增加等待时间 else: # 等待视频列表加载 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, 'li.SwZLHMKk')) ) except Exception as e: print(f"等待页面加载超时: {str(e)}") time.sleep(3) # 额外等待时间 # 获取滚动次数和延迟 scroll_times = int(self.scroll_count.get()) delay = float(self.delay.get()) # 开始滚动和采集 last_height = driver.execute_script("return document.body.scrollHeight") for i in range(scroll_times): if not self.is_running: break try: # 滚动页面 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(delay) # 检查是否到达底部 new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: print("已到达页面底部") break last_height = new_height # 获取页面源码并解析 page_source = driver.page_source soup = BeautifulSoup(page_source, 'html.parser') # 根据搜索类型选择不同的提取方法 if search_type == 'user': new_data = self.extract_user_data(soup) else: container = soup.select_one('[data-e2e="scroll-list"]') if container: new_data = self.extract_video_items(container) else: print("未找到视频列表容器") continue print(f"本次滚动找到 {len(new_data)} 条新数据") # 添加新数据(去重) for data in new_data: if data not in self.collected_data: self.collected_data.append(data) print(f"当前总共采集 {len(self.collected_data)} 条数据") # 更新数据显示 self.root.after(0, self.update_data_display) # 使用after确保在主线程中更新UI # 更新状态 self.status_label.config(text=f"正在滚动... ({i+1}/{scroll_times})") self.progress['value'] = (i + 1) / scroll_times * 100 except Exception as e: print(f"滚动错误: {str(e)}") continue print("搜索结果采集完成") self.status_label.config(text=f"采集完成,共获取{len(self.collected_data)}条数据") except Exception as e: print(f"搜索采集过程出错: {str(e)}") messagebox.showerror("错误", f"采集过程出错: {str(e)}") finally: self.is_running = False if driver: driver.quit() def extract_video_data(self, html): """提取数据""" if self.search_type.get() == 'user': return self.extract_user_data(html) else: return self.extract_video_items(html) def extract_user_data(self, html): """提取用户数据""" print("开始提取用户数据...") # 使用正确的选择器定位用户列表 user_items = html.select("div.search-result-card > a.hY8lWHgA.poLTDMYS") # 更新选择器 print(f"找到 {len(user_items)} 个用户项") user_data = [] for item in user_items: try: # 获取用户链接 user_link = item.get('href', '') # 获取标题 title_elem = item.select_one('div.XQwChAbX p.v9LWb7QE span span span span span') title = title_elem.get_text(strip=True) if title_elem else '' # 获取头像URL avatar_elem = item.select_one('img.RlLOO79h') avatar_url = avatar_elem.get('src', '') if avatar_elem else '' # 获取统计数据 stats_div = item.select_one('div.jjebLXt0') douyin_id = '' likes = '0' followers = '0' if stats_div: spans = stats_div.select('span') for span in spans: text = span.get_text(strip=True) print(f"处理span文本: {text}") # 调试输出 if '抖音号:' in text or '抖音号:' in text: id_span = span.select_one('span') if id_span: douyin_id = id_span.get_text(strip=True) elif '获赞' in text: likes = text.replace('获赞', '').strip() elif '粉丝' in text: followers = text.replace('粉丝', '').strip() # 获取简介 desc_elem = item.select_one('p.Kdb5Km3i span span span span span') description = desc_elem.get_text(strip=True) if desc_elem else '' # 构建数据 data = { 'title': title, 'douyin_id': douyin_id, 'likes': likes, 'followers': followers, 'description': description, 'avatar_url': avatar_url, 'user_link': user_link } # 清理数据 data = {k: self.clean_text(str(v)) for k, v in data.items()} # 格式化数字 data['likes'] = self.format_number(data['likes']) data['followers'] = self.format_number(data['followers']) # 处理用户链接 if data['user_link'] and not data['user_link'].startswith('http'): data['user_link'] = 'https://www.douyin.com' + data['user_link'] # 打印调试信息 print("\n提取到的数据:") for key, value in data.items(): print(f"{key}: {value}") # 只要有标题就添加 if data['title']: if data not in user_data: # 确保不重复添加 user_data.append(data) print(f"成功提取用户数据: {data['title']}") except Exception as e: print(f"提取单个用户数据错误: {str(e)}") traceback.print_exc() # 打印完整的错误堆栈 continue print(f"总共提取到 {len(user_data)} 条用户数据") return user_data def _extract_basic_info(self, item): """提取基本信息""" # 获取用户链接 user_link = item.select_one('a.uz1VJwFY') # 使用确切的类名 # 获取标题 title = "" title_elem = item.select_one('p.ZMZLqKYm span') # 使用确切的类名和结构 if title_elem: title = title_elem.get_text(strip=True) # 获取头像URL avatar_elem = item.select_one('img.fiWP27dC') avatar_url = avatar_elem.get('src', '') if avatar_elem else '' return { 'title': title, 'douyin_id': '', 'likes': '', 'followers': '', 'description': '', 'avatar_url': avatar_url, 'user_link': user_link.get('href', '') if user_link else '' } def _extract_stats_info(self, item, data): """提取统计信息""" stats_div = item.select_one('div.Y6iuJGlc') # 使用确切的类名 if stats_div: spans = stats_div.select('span') spans_text = [span.get_text(strip=True) for span in spans] print(f"找到的span文本: {spans_text}") # 调试输出 for text in spans_text: if '抖音号:' in text or '抖音号:' in text: # 获取嵌套的span中的抖音号 nested_span = stats_div.select_one('span > span') if nested_span: data['douyin_id'] = nested_span.get_text(strip=True) elif '获赞' in text: data['likes'] = text.replace('获赞', '').strip() elif '粉丝' in text: data['followers'] = text.replace('粉丝', '').strip() def _extract_description(self, item, data): """提取用户简介""" desc_elem = item.select_one('p.NYqiIDUo span') # 使用确切的类名和结构 if desc_elem: # 获取纯文本内容,去除表情图片 text_nodes = [node for node in desc_elem.stripped_strings] data['description'] = ' '.join(text_nodes) def _clean_and_format_data(self, data): """清理和格式化数据""" # 清理文本数据 for key in data: if isinstance(data[key], str): data[key] = self.clean_text(data[key]) # 格式化数字 data['likes'] = self.format_number(data['likes']) data['followers'] = self.format_number(data['followers']) # 处理用户链接 if data['user_link']: link = data['user_link'] # 移除查询参数 if '?' in link: link = link.split('?')[0] # 确保正确的格式 if link.startswith('//'): link = 'https:' + link elif not link.startswith('http'): # 移除可能的重复路径 link = link.replace('www.douyin.com/', '') link = link.replace('//', '/') if not link.startswith('/'): link = '/' + link link = 'https://www.douyin.com' + link print(f"原始链接: {data['user_link']}") # 调试输出 print(f"处理后链接: {link}") # 调试输出 data['user_link'] = link def _print_debug_info(self, data): """打印调试信息""" print("\n提取到的数据:") print(f"标题: {data['title']}") print(f"抖音号: {data['douyin_id']}") print(f"获赞: {data['likes']}") print(f"粉丝: {data['followers']}") print(f"简介: {data['description'][:50]}...") print(f"链接: {data['user_link']}") def extract_video_items(self, html): """提取视频数据(原有代码)""" video_items = html.select("li.SwZLHMKk") video_data = [] for item in video_items: try: # 获取视频链接 video_link = item.select_one('a.hY8lWHgA') if not video_link: continue # 构建数据 data = { 'video_url': video_link['href'].strip(), 'cover_image': item.select_one('img')['src'].strip() if item.select_one('img') else '', 'title': item.select_one('div.VDYK8Xd7').text.strip() if item.select_one('div.VDYK8Xd7') else '无标题', 'author': item.select_one('span.MZNczJmS').text.strip() if item.select_one('span.MZNczJmS') else '未知作者', 'publish_time': item.select_one('span.faDtinfi').text.strip() if item.select_one('span.faDtinfi') else '', 'likes': item.select_one('span.cIiU4Muu').text.strip() if item.select_one('span.cIiU4Muu') else '0' } # 清理数据 data = {k: self.clean_text(str(v)) for k, v in data.items()} # 验证数据完整性 if all(data.values()): video_data.append(data) else: print(f"跳过不完整数据: {data}") except Exception as e: print(f"提取单个视频数据错误: {str(e)}") continue return video_data def update_data_display(self): """更新数据显示""" try: search_type = self.search_type.get() print(f"更新数据显示,搜索类型: {search_type}") print(f"当前数据数量: {len(self.collected_data)}") if search_type == 'user': self.notebook.select(2) # 先切换到用户数据标签页 self.root.after(100, self.update_user_display) # 延迟一小段时间后更新显示 else: self.notebook.select(1) # 切换到视频数据标签页 self.root.after(100, self.update_video_display) except Exception as e: print(f"更新数据显示错误: {str(e)}") def update_user_display(self): """更新用户数据显示""" try: # 清空现有显示 self.user_tree.delete(*self.user_tree.get_children()) # 添加新数据 for i, data in enumerate(self.collected_data): try: # 格式化简介 description = data.get('description', '') if len(description) > 50: description = description[:47] + '...' # 格式化数据 values = ( i + 1, data.get('title', ''), data.get('douyin_id', ''), self.format_number(str(data.get('likes', '0'))), self.format_number(str(data.get('followers', '0'))), description, data.get('user_link', ''), data.get('avatar_url', '') ) self.user_tree.insert('', 'end', values=values) print(f"显示用户数据: {data.get('title', '')}") except Exception as e: print(f"处理单条用户数据显示错误: {str(e)}") continue # 更新统计 self.user_stats_label.config(text=f"共采集到 {len(self.collected_data)} 位用户") print(f"更新用户统计: {len(self.collected_data)} 位用户") # 自动滚动到最新数据 if self.user_tree.get_children(): self.user_tree.see(self.user_tree.get_children()[-1]) except Exception as e: print(f"更新用户数据显示错误: {str(e)}") def update_video_display(self): """更新视频数据显示(原有的update_data_display逻辑)""" try: # 清空现有显示 self.data_tree.delete(*self.data_tree.get_children()) # 添加新数据 for i, data in enumerate(self.collected_data): try: title = data.get('title', '') if len(title) > 50: title = title[:47] + '...' values = ( i + 1, title, data.get('author', '未知作者'), data.get('publish_time', ''), self.format_number(str(data.get('likes', '0'))), data.get('video_url', '') ) self.data_tree.insert('', 'end', values=values) except Exception as e: print(f"处理单条数据显示错误: {str(e)}") continue # 更新统计 self.stats_label.config(text=f"共采集到 {len(self.collected_data)} 条数据") # 自动滚动到最新数据 if self.data_tree.get_children(): self.data_tree.see(self.data_tree.get_children()[-1]) except Exception as e: print(f"更新数据显示错误: {str(e)}") def update_data_stats(self): """更新数据统计""" try: total_count = len(self.collected_data) self.stats_label.config(text=f"共采集到 {total_count} 条数据") except Exception as e: print(f"更新统计信息错误: {str(e)}") def stop_collection(self): """停止数据采集""" if self.is_running: self.is_running = False self.status_label.config(text="已停止采集") print("采集已停止") else: print("当前没有正在进行的采集任务") def export_excel(self): """导出数据到Excel""" if not self.collected_data: messagebox.showwarning("警告", "没有数据可导出!") return try: filename = f"抖音数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx" df = pd.DataFrame(self.collected_data) df.to_excel(filename, index=False) messagebox.showinfo("成功", f"数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出Excel失败: {str(e)}") def export_json(self): """导出数据到JSON""" if not self.collected_data: messagebox.showwarning("警告", "没有数据可导出!") return try: filename = f"抖音数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump(self.collected_data, f, ensure_ascii=False, indent=2) messagebox.showinfo("成功", f"数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出JSON失败: {str(e)}") def export_user_excel(self): """导出用户数据到Excel""" if not self.collected_data or self.search_type.get() != 'user': messagebox.showwarning("警告", "没有用户数据可导出!") return try: filename = f"抖音用户数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx" df = pd.DataFrame(self.collected_data) df.to_excel(filename, index=False) messagebox.showinfo("成功", f"用户数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出Excel失败: {str(e)}") def export_user_json(self): """导出用户数据到JSON""" if not self.collected_data or self.search_type.get() != 'user': messagebox.showwarning("警告", "没有用户数据可导出!") return try: filename = f"抖音用户数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump(self.collected_data, f, ensure_ascii=False, indent=2) messagebox.showinfo("成功", f"用户数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出JSON失败: {str(e)}") def clean_text(self, text): """清理文本""" return text.replace('\n', ' ').replace('\r', '').strip() def format_number(self, num_str): """格式化数字字符串""" try: num = int(num_str) if num >= 10000: return f"{num / 10000:.1f}万" return str(num) except ValueError: return num_str def analyze_interaction_data(self): """分析互动数据""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 将点赞数转换为数字 likes_data = [] for data in self.collected_data: likes = str(data['likes']) try: if '万' in likes: # 处理带"万"的数字 num = float(likes.replace('万', '')) * 10000 likes_data.append(int(num)) else: # 处理普通数字 likes_data.append(int(likes)) except (ValueError, TypeError): print(f"无法解析的点赞数: {likes}") continue # 计算统计数据 total_likes = sum(likes_data) avg_likes = total_likes / len(likes_data) if likes_data else 0 max_likes = max(likes_data) if likes_data else 0 # 生成报告 report = "===== 互动数据分析报告 =====\n\n" report += f"总视频数: {len(self.collected_data)}\n" report += f"总点赞数: {self.format_large_number(total_likes)}\n" report += f"平均点赞数: {self.format_large_number(int(avg_likes))}\n" report += f"最高点赞数: {self.format_large_number(max_likes)}\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: print(f"互动数据分析错误: {str(e)}") messagebox.showerror("错误", f"分析失败: {str(e)}") def format_large_number(self, num): """格式化大数字显示""" if num >= 10000: return f"{num/10000:.1f}万" return str(num) def analyze_content_length(self): """分析内容长度""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 计算标题长度 title_lengths = [len(data['title']) for data in self.collected_data] # 计算统计数据 avg_length = sum(title_lengths) / len(title_lengths) max_length = max(title_lengths) min_length = min(title_lengths) # 生成报告 report = "===== 内容长度分析报告 =====\n\n" report += f"平均标题长度: {avg_length:.1f}字\n" report += f"最长标题: {max_length}字\n" report += f"最短标题: {min_length}字\n\n" # 添加长度分布统计 length_ranges = [(0, 10), (11, 20), (21, 30), (31, 50), (51, 100), (101, float('inf'))] report += "标题长度分布:\n" for start, end in length_ranges: count = sum(1 for length in title_lengths if start <= length <= end) range_text = f"{start}-{end}字" if end != float('inf') else f"{start}字以上" percentage = (count / len(title_lengths)) * 100 report += f"{range_text}: {count}个 ({percentage:.1f}%)\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: messagebox.showerror("错误", f"分析失败: {str(e)}") def analyze_keywords(self): """分析标题中的高频词汇""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 合并所有标题文本 all_titles = ' '.join(data['title'] for data in self.collected_data) # 设置停用词 stop_words = { '的', '了', '是', '在', '我', '有', '和', '就', '都', '而', '及', '与', '着', '或', '等', '为', '一个', '没有', '这个', '那个', '但是', '而且', '只是', '不过', '这样', '一样', '一直', '一些', '这', '那', '也', '你', '我们', '他们', '它们', '把', '被', '让', '向', '往', '但', '去', '又', '能', '好', '给', '到', '看', '想', '要', '会', '多', '能', '这些', '那些', '什么', '怎么', '如何', '为什么', '可以', '因为', '所以', '应该', '可能', '应该' } # 使用jieba进行分词 words = [] for word in jieba.cut(all_titles): if len(word) > 1 and word not in stop_words: # 过滤单字词和停用词 words.append(word) # 统计词频 word_counts = Counter(words) # 生成报告 report = "===== 高频词汇分析报告 =====\n\n" report += f"总标题数: {len(self.collected_data)}\n" report += f"总词汇量: {len(words)}\n" report += f"不同词汇数: {len(word_counts)}\n\n" # 显示高频词汇(TOP 100) report += "高频词汇 TOP 100:\n" report += "-" * 40 + "\n" report += "排名\t词汇\t\t出现次数\t频率\n" report += "-" * 40 + "\n" for rank, (word, count) in enumerate(word_counts.most_common(100), 1): frequency = (count / len(words)) * 100 report += f"{rank}\t{word}\t\t{count}\t\t{frequency:.2f}%\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: print(f"高频词汇分析错误: {str(e)}") messagebox.showerror("错误", f"分析失败: {str(e)}") def treeview_sort_column(self, tree, col, reverse): """列排序函数""" # 获取所有项目 l = [(tree.set(k, col), k) for k in tree.get_children('')] try: # 尝试将数值型数据转换为数字进行排序 if col in ['序号', '获赞数', '粉丝数', '点赞数']: # 处理带"万"的数字 def convert_number(x): try: if '万' in x[0]: return float(x[0].replace('万', '')) * 10000 return float(x[0]) except ValueError: return 0 l.sort(key=convert_number, reverse=reverse) else: # 字符串排序 l.sort(reverse=reverse) except Exception as e: print(f"排序错误: {str(e)}") # 如果转换失败,按字符串排序 l.sort(reverse=reverse) # 重新排列项目 for index, (val, k) in enumerate(l): tree.move(k, '', index) # 更新序号 tree.set(k, '序号', str(index + 1)) # 切换排序方向 tree.heading(col, command=lambda: self.treeview_sort_column(tree, col, not reverse)) def create_help_tab(self): """创建帮助标签页""" help_frame = ttk.Frame(self.notebook) self.notebook.add(help_frame, text='使用帮助') # 创建帮助文本框 help_text = tk.Text(help_frame, wrap=tk.WORD, padx=10, pady=10) help_text.pack(fill='both', expand=True) # 添加滚动条 scrollbar = ttk.Scrollbar(help_frame, orient='vertical', command=help_text.yview) scrollbar.pack(side='right', fill='y') help_text.configure(yscrollcommand=scrollbar.set) # 帮助内容 help_content = """ 抖音作品分析工具使用指南 ==================== 1. 数据采集 ----------------- • 支持两种采集方式: - 直接输入抖音链接 - 关键词搜索采集 • 关键词搜索支持以下类型: - 视频搜索 - 用户搜索 - 音乐搜索 - 话题搜索 • 采集参数说明: - 滚动次数:决定采集数据量的多少 - 延迟(秒):每次滚动的等待时间,建议2-3秒 • 使用技巧: - 采集时可随时点击"停止采集" - 建议设置适当的延迟避免被限制 - 数据采集过程中请勿关闭浏览器窗口 2. 数据查看 ----------------- • 视频数据: - 包含标题、作者、发布时间等信息 - 双击可直接打开视频链接 - 支持按列排序 - 可导出为Excel或JSON格式 • 用户数据: - 显示用户名、抖音号、粉丝数等信息 - 双击可打开用户主页 - 支持数据排序 - 可单独导出用户数据 3. 数据分析 ----------------- • 互动数据分析: - 统计总点赞数、平均点赞等指标 - 展示互动数据分布情况 • 内容长度分析: - 分析标题长度分布 - 显示最长/最短标题统计 • 高频词汇分析: - 提取标题中的关键词 - 展示TOP100高频词汇 - 计算词频占比 4. 常见问题 ----------------- Q: 为什么采集速度较慢? A: 为了避免被反爬虫机制拦截,程序设置了延迟机制。 Q: 如何提高采集成功率? A: 建议: - 设置适当的延迟时间(2-3秒) - 避免过于频繁的采集 - 确保网络连接稳定 Q: 数据导出格式说明? A: 支持两种格式: - Excel格式:适合数据分析和处理 - JSON格式:适合数据备份和程序读取 Q: 如何处理采集失败? A: 可以: - 检查网络连接 - 增加延迟时间 - 减少单次采集数量 - 更换搜索关键词 5. 注意事项 ----------------- • 合理使用: - 遵守抖音平台规则 - 避免频繁、大量采集 - 合理设置采集参数 • 数据安全: - 及时导出重要数据 - 定期备份采集结果 • 使用建议: - 建议使用稳定的网络连接 - 采集时避免其他浏览器操作 - 定期清理浏览器缓存 如需更多帮助,请参考项目文档或联系开发者。 """ # 插入帮助内容 help_text.insert('1.0', help_content) help_text.config(state='disabled') # 设置为只读 if __name__ == "__main__": root = tk.Tk() app = DouyinAnalyzer(root) root.mainloop() #您下载的资源来自www.fulicode.cn三、下载指南 123云盘下载 抖音数据采集分析工具.zip 下载地址:https://www.123684.com/s/rCKrjv-Vpb8d? 提取码:vq7x无论你是经验丰富的专业开发者,能够熟练地对代码进行二次开发与定制;还是对抖音数据满怀热忱、刚刚踏入数据领域的爱好者,渴望通过数据了解抖音世界的奥秘,都能毫无门槛地获取这份宝贵的资源。我们衷心希望这款工具能够在你的创作与分析旅程中发挥重要作用,帮助你在抖音平台的创作之路上更加得心应手,在市场分析领域取得更优异的成果,开启属于自己的数据洞察新征程。
-
QQ 号 API 获取用户高清头像教程及多语言代码 借助QQ号API获取用户高清QQ头像与昵称的实用指南 在投身Typecho开发、WordPress开发,亦或是其他涉及QQ用户的项目进程中,获取用户头像这一需求极为常见。经过一番探寻,我成功找到了可获取QQ高清头像的API接口,在此迫不及待地想要分享给大家。 调用截图 调用截图图片 一、普通头像API 普通头像的获取,可借助以下两个API地址实现: http://q1.qlogo.cn/g?b=qq&nk=QQ号码&s=100 在实际访问这个链接时,我们以QQ号码为123456789为例,当将其替换到链接中的QQ号码位置后,完整链接变为http://q1.qlogo.cn/g?b=qq&nk=123456789&s=100。通过访问此链接,便可得到该QQ号码对应的尺寸为100×100像素的普通头像。这一API接口能够稳定地提供普通尺寸的头像资源,适用于对头像清晰度要求不高,仅需快速展示头像的场景,例如一些列表页面,对头像清晰度的需求低于对加载速度的要求。 http://q2.qlogo.cn/headimg_dl?dst_uin=QQ号码&spec=100 同样以QQ号码123456789为例,替换后链接为http://q2.qlogo.cn/headimg_dl?dst_uin=123456789&spec=100。访问该链接,同样能获取到尺寸为100×100像素的普通头像。这个API与第一个类似,都是提供普通尺寸头像的获取途径,项目开发者可以根据实际的项目架构和需求,灵活选择使用。 二、高清头像API 若期望获取高清头像,可使用如下API:http://q.qlogo.cn/headimg_dl?dst_uin=QQ号码&spec=640&img_type=jpg。 当使用QQ号码123456789时,链接会变成http://q.qlogo.cn/headimg_dl?dst_uin=123456789&spec=640&img_type=jpg。访问修改后的链接,就能得到分辨率较高、细节更为丰富的高清头像,其尺寸达到640×640像素 ,格式为JPG。在项目中,若需要展示头像细节,或者在一些重要的展示区域使用头像,高清头像就显得尤为重要,这个API接口就为我们提供了这样的资源。 三、QQ昵称API(已失效) 曾经可用于获取QQ昵称的API为http://users.qzone.qq.com/fcg-bin/cgi_get_portrait.fcg?uins=QQ号码。以QQ号码123456789为例,替换后链接为http://users.qzone.qq.com/fcg-bin/cgi_get_portrait.fcg?uins=123456789,在该API失效前,访问链接可得到对应QQ号码的昵称。但目前此接口已无法正常使用,若项目中需要获取QQ昵称,开发者需寻找其他替代方案,比如尝试通过QQ互联平台等正规渠道申请相关接口权限,以满足获取昵称的需求。 四、示例调用代码 下面为大家提供多种语言调用上述头像API的示例代码,帮助大家更好地在项目中实现头像获取功能。 Python import requests def get_qq_avatar(qq_number, is_high_quality=True): if is_high_quality: api_url = f"http://q.qlogo.cn/headimg_dl?dst_uin={qq_number}&spec=640&img_type=jpg" else: api_url = f"http://q1.qlogo.cn/g?b=qq&nk={qq_number}&s=100" response = requests.get(api_url) if response.status_code == 200: with open(f"{qq_number}_avatar.jpg", "wb") as f: f.write(response.content) print(f"成功获取{'高清' if is_high_quality else '普通'}头像并保存为{qq_number}_avatar.jpg") else: print(f"获取头像失败,状态码:{response.status_code}") qq_number = "123456789" get_qq_avatar(qq_number, is_high_quality=True) get_qq_avatar(qq_number, is_high_quality=False)Java import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.URL; import java.net.URLConnection; public class QQAvatarFetcher { public static void getQQAvatar(String qqNumber, boolean isHighQuality) { String apiUrl; if (isHighQuality) { apiUrl = String.format("http://q.qlogo.cn/headimg_dl?dst_uin=%s&spec=640&img_type=jpg", qqNumber); } else { apiUrl = String.format("http://q1.qlogo.cn/g?b=qq&nk=%s&s=100", qqNumber); } try { URL url = new URL(apiUrl); URLConnection connection = url.openConnection(); InputStream inputStream = connection.getInputStream(); FileOutputStream outputStream = new FileOutputStream(String.format("%s_avatar.jpg", qqNumber)); byte[] buffer = new byte[1024]; int bytesRead; while ((bytesRead = inputStream.read(buffer)) != -1) { outputStream.write(buffer, 0, bytesRead); } outputStream.close(); inputStream.close(); System.out.println(String.format("成功获取%s头像并保存为%s_avatar.jpg", isHighQuality ? "高清" : "普通", qqNumber)); } catch (IOException e) { System.out.println(String.format("获取头像失败:%s", e.getMessage())); } } public static void main(String[] args) { String qqNumber = "123456789"; getQQAvatar(qqNumber, true); getQQAvatar(qqNumber, false); } }JavaScript(Node.js环境) const https = require('https'); const fs = require('fs'); function getQQAvatar(qqNumber, isHighQuality) { let apiUrl; if (isHighQuality) { apiUrl = `http://q.qlogo.cn/headimg_dl?dst_uin=${qqNumber}&spec=640&img_type=jpg`; } else { apiUrl = `http://q1.qlogo.cn/g?b=qq&nk=${qqNumber}&s=100`; } https.get(apiUrl, (response) => { const filePath = `${qqNumber}_avatar.jpg`; const fileStream = fs.createWriteStream(filePath); response.pipe(fileStream); fileStream.on('finish', () => { console.log(`成功获取${isHighQuality ? '高清' : '普通'}头像并保存为${filePath}`); }); response.on('error', (error) => { console.log(`获取头像失败:${error.message}`); }); }); } const qqNumber = "123456789"; getQQAvatar(qqNumber, true); getQQAvatar(qqNumber, false);C using System; using System.IO; using System.Net; class Program { static void GetQQAvatar(string qqNumber, bool isHighQuality) { string apiUrl; if (isHighQuality) { apiUrl = string.Format("http://q.qlogo.cn/headimg_dl?dst_uin={0}&spec=640&img_type=jpg", qqNumber); } else { apiUrl = string.Format("http://q1.qlogo.cn/g?b=qq&nk={0}&s=100", qqNumber); } try { WebRequest request = WebRequest.Create(apiUrl); using (WebResponse response = request.GetResponse()) using (Stream inputStream = response.GetResponseStream()) using (FileStream outputStream = new FileStream($"{qqNumber}_avatar.jpg", FileMode.Create)) { byte[] buffer = new byte[1024]; int bytesRead; while ((bytesRead = inputStream.Read(buffer, 0, buffer.Length)) > 0) { outputStream.Write(buffer, 0, bytesRead); } } Console.WriteLine($"成功获取{(isHighQuality ? "高清" : "普通")}头像并保存为{qqNumber}_avatar.jpg"); } catch (Exception ex) { Console.WriteLine($"获取头像失败:{ex.Message}"); } } static void Main() { string qqNumber = "123456789"; GetQQAvatar(qqNumber, true); GetQQAvatar(qqNumber, false); } }PHP <?php function getQQAvatar($qqNumber, $isHighQuality = true) { if ($isHighQuality) { $apiUrl = "http://q.qlogo.cn/headimg_dl?dst_uin={$qqNumber}&spec=640&img_type=jpg"; } else { $apiUrl = "http://q1.qlogo.cn/g?b=qq&nk={$qqNumber}&s=100"; } $imgData = file_get_contents($apiUrl); if ($imgData !== false) { $fileName = $isHighQuality ? "{$qqNumber}_high_quality_avatar.jpg" : "{$qqNumber}_avatar.jpg"; file_put_contents($fileName, $imgData); echo "成功获取" . ($isHighQuality ? "高清" : "普通") . "头像并保存为{$fileName}<br>"; } else { echo "获取头像失败<br>"; } } $qqNumber = "123456789"; getQQAvatar($qqNumber, true); getQQAvatar($qqNumber, false); ?>Go package main import ( "fmt" "io" "log" "net/http" "os" ) func getQQAvatar(qqNumber string, isHighQuality bool) { var apiUrl string if isHighQuality { apiUrl = fmt.Sprintf("http://q.qlogo.cn/headimg_dl?dst_uin=%s&spec=640&img_type=jpg", qqNumber) } else { apiUrl = fmt.Sprintf("http://q1.qlogo.cn/g?b=qq&nk=%s&s=100", qqNumber) } resp, err := http.Get(apiUrl) if err != nil { log.Fatalf("获取头像失败: %v", err) } defer resp.Body.Close() out, err := os.Create(fmt.Sprintf("%s_avatar.jpg", qqNumber)) if err != nil { log.Fatalf("创建文件失败: %v", err) } defer out.Close() _, err = io.Copy(out, resp.Body) if err != nil { log.Fatalf("写入文件失败: %v", err) } fmt.Printf("成功获取%s头像并保存为%s_avatar.jpg\n", func() string { if isHighQuality { return "高清" } return "普通" }(), qqNumber) } func main() { qqNumber := "123456789" getQQAvatar(qqNumber, true) getQQAvatar(qqNumber, false) }Ruby require 'net/http' require 'uri' def get_qq_avatar(qq_number, is_high_quality) if is_high_quality api_url = "http://q.qlogo.cn/headimg_dl?dst_uin=#{qq_number}&spec=640&img_type=jpg" else api_url = "http://q1.qlogo.cn/g?b=qq&nk=#{qq_number}&s=100" end uri = URI(api_url) response = Net::HTTP.get(uri) file_name = "#{qq_number}_#{is_high_quality ? 'high_quality_' : ''}avatar.jpg" File.write(file_name, response) puts "成功获取#{is_high_quality ? '高清' : '普通'}头像并保存为#{file_name}" rescue StandardError => e puts "获取头像失败: #{e.message}" end qq_number = "123456789" get_qq_avatar(qq_number, true) get_qq_avatar(qq_number, false)Swift(用于iOS/macOS开发,需在合适的项目环境中运行) import Foundation func getQQAvatar(qqNumber: String, isHighQuality: Bool, completion: @escaping (Result<Data, Error>) -> Void) { let apiUrl: String if isHighQuality { apiUrl = "http://q.qlogo.cn/headimg_dl?dst_uin=\(qqNumber)&spec=640&img_type=jpg" } else { apiUrl = "http://q1.qlogo.cn/g?b=qq&nk=\(qqNumber)&s=100" } guard let url = URL(string: apiUrl) else { completion(.failure(NSError(domain: "Invalid URL", code: 0, userInfo: nil))) return } URLSession.shared.dataTask(with: url) { data, response, error in if let error = error { completion(.failure(error)) return } guard let data = data else { completion(.failure(NSError(domain: "No data received", code: 0, userInfo: nil))) return } completion(.success(data)) }.resume() } let qqNumber = "123456789" getQQAvatar(qqNumber: qqNumber, isHighQuality: true) { result in switch result { case .success(let data): let filePath = "\(NSTemporaryDirectory())\(qqNumber)_high_quality_avatar.jpg" do { try data.write(to: URL(fileURLWithPath: filePath)) print("成功获取高清头像并保存到\(filePath)") } catch { print("保存高清头像失败: \(error)") } case .failure(let error): print("获取高清头像失败: \(error)") } } getQQAvatar(qqNumber: qqNumber, isHighQuality: false) { result in switch result { case .success(let data): let filePath = "\(NSTemporaryDirectory())\(qqNumber)_avatar.jpg" do { try data.write(to: URL(fileURLWithPath: filePath)) print("成功获取普通头像并保存到\(filePath)") } catch { print("保存普通头像失败: \(error)") } case .failure(let error): print("获取普通头像失败: \(error)") } }上述代码在各自语言环境下,根据传入的QQ号码和是否获取高清头像的参数,从对应的API获取头像数据,并将头像保存为本地文件。在实际使用中,请确保你的环境满足相应语言和库的运行要求,同时注意处理可能出现的网络请求错误和文件操作错误。另外,由于网络环境和QQ服务器的限制,实际运行效果可能会有所不同。
-
彩虹易支付:一款免签约支付产品 源码名字 彩虹易支付源码介绍 这是一款开源性质的免签约支付产品,它宛如一座桥梁,在开发者与多种支付方式之间搭建起了便捷通道。它能够助力开发者一站式轻松接入包括广受欢迎的支付宝、使用频率极高的微信、可靠的财付通、便捷的 QQ 钱包等在内的多种支付方式,从而极大地提高了支付集成的效率,让支付流程变得更加顺畅和高效。值得一提的是,目前该系统的最新版本已经于 2024 年 5 月 1 日正式发布,这一版本的发布为用户带来了更多优质的体验和更稳定的性能。源码截图 首页截图 首页截图图片 登录界面 登录界面图片 环境要求 PHP ≥7.1 MySQL ≥5.6安装教程 1.上传源码至空间,确保环境符合要求 2.访问域名/install 3.设置伪静态规则,在目录下有一个nginx.txt文件,将他复制到伪静态中,否则付款回调404!源码下载 直链下载 下载地址:https://file.fulicode.cn/down.php/7508a56cf617c1d8a782e711dc6b303f.zip 提取码: 现在昔日云提供低价服务器,配置还好。可以用于搭建本源码 带你去昔日云
-
深得用户肯定和信赖的主机系统:梦奈宝塔 源码介绍 梦奈宝塔主机系统(简称MNBT)是一款专为用户提供高效、便捷服务的主机管理系统。该系统致力于支持用户进行单个或多个宝塔面板主机的销售与管理,旨在简化操作流程,提升管理效率。 MNBT自推出以来,凭借其开源的特性、免费的使用模式、卓越的用户体验以及持续的更新迭代,赢得了广大用户的信赖与好评。其开源设计不仅赋予了用户高度的自由度,还促进了社区的共同参与和持续发展;免费的使用模式则大大降低了用户的使用门槛,使得更多人能够轻松上手,享受技术带来的便利。 此外,MNBT始终秉持“好用”的设计理念,界面友好,功能齐全,操作简便,让用户能够快速上手并高效完成任务。系统还坚持“持久更新”的原则,不断优化和完善各项功能,确保用户始终能够享受到最新的技术成果和安全保障。源码截图 有图有真相 首页图片源码更新 这可不是烂尾工程,而是有在更新的项目! [重要]目前支持对接魔方、SWAPIDC [重要]本系统已经适配Windows,目前可对接Windows和Linux的宝塔 [重要]新增一键修复(在后台右上角,可修复MNBT由于更新或者API变更导致的数据错误等) [新增]新增一个主机类型:CDN [新增]增加了域名售卖功能 [新增]新增重命名文件/文件夹 [新增]新增产品流量控制 [新增]后台添加logo和版权修改功能 [新增]后台API管理新增默认建站PHP版本修改 [新增]后台API管理新增修改Linux/Windows的建站目录 [新增]增加了更多小细节 [优化]重写教程界面,现在更加直观了 [优化]在线文件上传新版本采用分片上传,现在支持断点续传了,支持显示当前所在目录 [优化]由于宝塔新版APi的变化,现已经修改完成,所有功能均可正常使用 [优化]重写系统安装页面,现在无需验证码即可安装! [优化]优化了旧代码,目前可以更加流畅地运行了 [修复]修复一键部署在配置不够的情况下可以绕前端部署的问题 SWAPIDC对接插件已经更新,请各位使用SWAPIDC对接MNBT的重新上传插件!下载链接 话不多说,上链接梦奈宝塔最新版1.76 下载地址:https://file.fulicode.cn/down.php/67147cd2c4dcf5ae4e8594c582e7a482.zip 提取码: 推荐服务器 现在昔日云提供超低价服务器,配置还好。 带你去昔日云低价服务器
-
Video.js:打造功能丰富、跨平台的自定义HTML5视频播放器 项目名字 Video.js在线示例 源码好不好,一看就知道 如果想使用video.js,请确保浏览器可以运行JavaScript,并且支持 HTML5 video 使用 方法一 在 jsdelivr 和 bootcdn 上都可以找到video.js的cdn,我们以jsdelivr为例。 需要引入的js和css如下:https://unpkg.com/video.js@7.10.2/dist/video-js.min.css https://unpkg.com/video.js@7.10.2/dist/video.min.js引入video.js 最简单的使用video.js的方式是创建一个video标签,并且包含data-setup属性。data-setup属性可以包含video.js的各种配置。如果什么都不需要,可以传一个空对象”{}”<video id="my-player" class="video-js" controls preload="auto" width="640" height="264" poster="http://vjs.zencdn.net/v/oceans.png" data-setup="{}" > <source src="http://vjs.zencdn.net/v/oceans.mp4" type="video/mp4" /> <p class="vjs-no-js"> 如果想使用video.js,请确保浏览器可以运行JavaScript,并且支持 <a href="https://videojs.com/html5-video-support/" target="_blank" >HTML5 video</a> </p> </video>页面加载完成后,video.js会找到该video标签,然后启动一个播放器。 完整代码如下:<head> <link href="https://unpkg.com/video.js@7.10.2/dist/video-js.min.css" rel="stylesheet" /> <!-- 如果要支持IE8,请使用v7之前的video.js,并且引入下面这个js链接。--> <!-- <script src="https://vjs.zencdn.net/ie8/1.1.2/videojs-ie8.min.js"></script> --> </head> <body> <video id="my-player" class="video-js" controls preload="auto" width="640" height="264" poster="http://vjs.zencdn.net/v/oceans.png" data-setup="{}" > <source src="http://vjs.zencdn.net/v/oceans.mp4" type="video/mp4" /> <p class="vjs-no-js"> 如果想使用video.js,请确保浏览器可以运行JavaScript,并且支持 <a href="https://videojs.com/html5-video-support/" target="_blank" >HTML5 video</a> </p> </video> <script src="https://unpkg.com/video.js@7.10.2/dist/video.min.js"></script> </body>js启动 如果不想自动启动播放器,可以移除video标签上的data-setup属性,然后使用js代码启动。let player = videojs('my-player');调用videojs函数的时候,也可以传options配置对象和callback回调函数作为参数。let options = {}; let player = videojs('my-player', options, function onPlayerReady() { videojs.log('播放器准备好了!'); // In this context, `this` is the player that was created by Video.js. this.play(); this.on('ended', function() { videojs.log('播放结束!'); }); });获取Video.js 获取Video.js 下载地址:https://file.fulicode.cn/down.php/854370b8fa22a27d81c6be1a79a28f98.zip 提取码: 结语 祝大家安装成功2024-11-16 14:14:03 星期六
-
亿乐社区源码:大家期待已久的高端商城 引言 这款亿乐社区源码,在大多数站点都是要钱的,现在我在福利源码免费分享它!源码截图 后台登录页 后台登录页图片 后台首页 后台首页图片 前台登录页 前台登录页图片 前台首页 前台首页图片 安装要求 宝塔支持go项目 数据库需要可以自定义 php7.2 支持反向代理 安装教程 增加对接 docking_site 增加分站 substation 增加域名 substation_domain 数据库账号 yile123471 密码 bNxechDdTfBJcES3 第一个解压在opt第二个上传到数据库3反向代理4添加GO5增加域名 http://127.0.0.1:10010 $host推荐货源 可以对接www.diligo.asia源码下载 隐藏内容,请前往内页查看详情 温馨提示:安装后及时修改密码 结语 祝大家用的愉快,不会的可以哔哩哔哩。2024-11-10 22:34:50 星期日
-
轻量级开源博客:typecho typecho介绍 Typecho 是一个轻量级的开源博客平台,它基于 PHP 语言开发,并使用 MySQL 数据库来存储数据。Typecho 的名字来源于 "Type" 和 "Echo" 的结合,意味着“表达”和“回声”,体现了其作为内容发布平台的本质。 Typecho 的设计理念是简洁、高效、易用,它提供了一个干净、简洁的用户界面,同时保持了强大的功能。Typecho 的代码结构清晰,易于扩展和定制,这使得它成为许多开发者和博客作者的首选源码截图 typecho图片 主要特点 1.轻量级: Typecho 的核心代码非常简洁,这使得它在服务器资源的使用上非常高效,适合于各种配置环境的服务器。 2.易于使用: 提供了直观的用户界面和易于理解的管理后台,使得用户可以快速上手并开始发布内容。 3.高度可定制: Typecho 的模板系统允许用户自定义网站的外观和布局,同时插件系统使得添加新功能变得简单。 4.Markdown 支持: Typecho 原生支持 Markdown 语法,这使得撰写和格式化文章变得非常方便。 5.响应式设计: Typecho 的默认模板是响应式的,这意味着#网站可以在各种设备上良好显示,包括桌面电脑、平板和手机。 6.社区支持: 作为一个开源项目,Typecho 拥有一个活跃的社区,用户可以在社区中寻求帮助、分享经验或贡献代码。 7.安全性: Typecho 的开发团队注重安全性,定期发布更新以修复漏洞和提升安全性。 安装typecho Typecho 的安装要求相对较低,主要是因为其轻量级的设计。以下是安装 Typecho 的一些基本要求:1.服务器环境: 支持 PHP 5.1 以上版本,推荐使用 PHP 7.2 或更高版本以获得更好的性能和安全性。 需要支持 MySQL 数据库(推荐 MySQL 5.0 以上版本)或 MariaDB 数据库。 需要支持 Apache 或 Nginx 等 Web 服务器。 2.PHP 扩展: 需要启用 PDO_MySQL 扩展以支持数据库连接。 推荐启用 mbstring、iconv、json 和 openssl 扩展以支持多语言、字符编码转换、JSON 处理和加密功能。 3.服务器配置: 需要配置好服务器的 URL 重写功能(如 Apache 的 mod_rewrite 或 Nginx 的 rewrite 规则)以支持友好的 URL 结构。 4.文件权限: 需要确保服务器上的文件权限设置正确,允许 Web 服务器用户对 Typecho 的安装目录进行读写操作。 5.其他: 需要一个域名或子域名指向你的服务器 IP 地址。 需要一个用于安装 Typecho 的数据库和数据库用户。 下载typecho 下载地址:https://github.com/typecho/typecho/releases/latest/download/typecho.zip 提取码: 结语 由于其轻量级和高效的特点,Typecho 特别适合那些希望拥有一个快速加载、简洁且易于管理的博客或网站的个人或小型团队。同时,对于那些希望深入定制网站功能和外观的开发者来说,Typecho 也是一个很好的选择。 现在昔日云提供免费虚拟主机,配置还好。足矣搭建typecho加上本主题 带你去昔日云免费主机 2024-11-02 22:56:01 星期六
-
wordpress百度推送插件:WP BaiDu Submit 插件介绍 百度推送插件可以实现网站文章自动推送到百度上,有效提升网站的收录量。如果网站里的原创内容不想被其它网站转走,最为快速的提交方式,建议您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录。插件下载 WordPress 百度推送插件下载,可以去在WordPress后台插件安装处搜索:WP BaiDu Submit。或者直接下载: 隐藏内容,请前往内页查看详情 下载插件 下载地址:https://wordpress.org/plugins/wp-baidu-submit/ 提取码: 安装与使用 WordPress 百度推送插件安装好之后,还需要先获取百度站长工具的准入密钥: 我们打开百度站长工具网站 我们点击登录,然后翻到下面自动提交的部分(如果没有验证网站的东西请去——我的网站——添加验证) 我们找到接口调用地址的token,在那链接的最后面,我这里是123456789。先纪录下这个token,我们等会要用到。 回到的网站,在安装插件后,后台的左侧会多出一个名为-BaiDu Submit-的设置栏,点击他 现在,我们把我们的验证的网站填入——验证站点域名——中,然后把我们刚刚记录下的token填入——站点准入密匙,按需求勾选相应功能。再点击保存更改我们就大功告成了~