找到
38
篇与
源码
相关的结果
-
 解锁高效开发新体验:极速后台开发框架FastAdmin FastAdmin:极速后台开发框架的全面解析 头图图片 前言 在当今软件开发的快节奏环境中,高效、稳定且功能强大的后台开发框架是开发者们梦寐以求的工具。一个优秀的框架不仅能大幅缩短开发周期,还能提升项目的整体质量和可维护性。FastAdmin,正是这样一款脱颖而出的基于ThinkPHP与Bootstrap深度融合的极速后台开发框架,它凭借丰富的特性和卓越的性能,在众多框架中占据了一席之地,深受开发者们的青睐。一、框架概述 FastAdmin的诞生,是技术融合与创新的结晶。ThinkPHP作为国内知名的PHP开发框架,以其简洁高效的代码风格、完善的MVC架构以及强大的数据库操作能力,为FastAdmin的后端开发筑牢根基。例如在处理复杂的业务逻辑和数据库交互时,ThinkPHP的Eloquent ORM(对象关系映射)功能,能让开发者以面向对象的方式轻松操作数据库,大大减少了SQL语句的编写量,提高了开发效率和代码的可读性。而Bootstrap,作为前端开发领域的佼佼者,以其简洁直观的设计理念、丰富多样的组件库以及出色的响应式布局,赋予了FastAdmin前端界面极高的美观度和用户友好性。无论是在大屏的PC端,还是小巧的手机屏幕上,FastAdmin的前端界面都能自适应,为用户提供一致且流畅的使用体验。 二、强大的权限管理系统 2.1 父子级权限继承 FastAdmin的权限管理系统依托于先进的Auth验证机制,为各类项目提供了精细化的权限控制方案。其中,无限层级的父子级权限继承功能尤为突出。想象一下,在一个大型连锁企业的管理系统中,企业总部的超级管理员作为顶级父级,拥有最高权限。他可以通过FastAdmin,为各个地区的区域经理分配不同的权限。比如,给予华东地区经理查看和修改该地区所有门店销售数据的权限,同时赋予其管理下属门店店长的权限。而门店店长作为子级,又可以进一步为店内的收银员、导购员等员工设置更为细致的操作权限,如收银员只能进行收款和退款操作,导购员只能查看商品库存和价格信息。这种层层递进的权限结构,确保了企业内部数据的安全流转和高效管理。 2.2 单管理员多角色模式 除了父子级权限继承,FastAdmin的单管理员多角色模式也为权限管理带来了极大的灵活性。以一个综合性的在线教育平台为例,平台的运营主管可能需要同时扮演课程管理员、学员管理专员和营销活动策划者等多个角色。在FastAdmin框架下,运营主管可以根据不同的业务场景,轻松切换角色。当进行课程管理时,切换到课程管理员角色,便拥有添加、编辑、删除课程以及设置课程价格和有效期等权限;在处理学员相关事务时,切换到学员管理专员角色,能够查看学员的学习进度、考试成绩,进行学员信息的修改和审核等操作;而在策划营销活动时,切换到营销活动策划者角色,可对活动的宣传文案、推广渠道等进行设置和管理。这种灵活的角色切换机制,避免了因权限限制而导致的工作流程繁琐问题,大大提高了管理员的工作效率。 2.3 数据管理权限 在数据管理方面,FastAdmin充分考虑了不同用户的实际需求。管理员既可以选择管理子级数据,从宏观层面掌控整个团队或组织的数据情况,以便进行数据分析和决策制定。例如在一个销售团队中,销售经理通过管理子级数据,可以查看每个销售人员的业绩报表,分析销售趋势,从而制定更合理的销售策略。也可以专注于个人数据的管理,确保个人负责的数据安全和隐私。比如,每个销售人员都可以对自己的客户信息进行单独管理,防止他人随意访问和修改,保护客户隐私。 三、卓越的一键生成功能 3.1 一键生成CRUD FastAdmin的一键生成CRUD功能,堪称开发过程中的“加速器”。在传统的项目开发中,创建控制器、模型、视图、JS、语言包、菜单以及回收站等基础模块,往往需要开发者耗费大量的时间和精力编写重复的代码。而FastAdmin的这一功能,极大地简化了开发流程。以一个简单的图书管理系统为例,开发者只需在FastAdmin的操作界面中,准确输入图书数据库表的结构信息,如书名、作者、出版社、出版日期等字段,以及相关的业务需求,如图书的添加、查询、借阅、归还等功能,然后轻轻点击一键生成按钮,系统便能在瞬间生成包含这些功能的完整CRUD代码。这不仅大大缩短了开发周期,还减少了因手动编写代码可能出现的错误,提高了代码的质量和一致性。 3.2 其他一键操作功能 除了一键生成CRUD,FastAdmin还提供了一系列便捷的一键操作功能,进一步提升了开发效率。一键压缩打包JS和CSS文件,能够有效优化前端资源的加载速度。在实际应用中,当项目上线后,大量分散的JS和CSS文件会增加浏览器的请求次数,从而延长页面的加载时间。通过FastAdmin的一键压缩打包功能,这些文件可以被合并成一个或几个文件,并进行压缩处理,减少了文件体积,加快了页面的加载速度,提升了用户体验。一键CDN静态资源部署功能,确保了项目的静态资源,如图片、样式文件和脚本文件等,能够在全球范围内快速分发。无论用户身处何地,都能迅速加载项目的相关资源,提高了应用的访问速度和稳定性。例如,对于一个面向全球用户的电商平台,通过CDN部署,欧洲的用户可以快速加载来自欧洲节点的静态资源,亚洲的用户则可以从亚洲节点获取,大大降低了网络延迟。一键生成控制器菜单和规则,使得菜单和权限规则的创建变得简单易懂。开发者只需按照系统提示,输入菜单名称、链接地址、所属模块等信息,即可快速创建出符合项目需求的菜单结构和对应的权限规则,避免了手动配置的繁琐和错误。一键生成API接口文档,为团队协作和接口对接提供了极大的便利。在多人协作开发项目中,清晰准确的API接口文档能够帮助不同的开发者快速了解接口的功能、参数要求和返回值格式,提高开发效率,减少因沟通不畅而导致的开发错误。 四、完善的前端功能组件开发 4.1 基于AdminLTE和Bootstrap的开发 FastAdmin的前端功能组件开发基于AdminLTE进行二次开发,充分汲取了AdminLTE简洁美观的设计风格和丰富实用的组件库。同时,以Bootstrap为基础,确保了前端界面的卓越响应式设计。在手机端,页面布局会自动适应屏幕尺寸,菜单通常会以折叠式的导航栏呈现,方便用户单手操作;按钮的大小和位置经过精心设计,便于用户点击。在平板端,页面的展示更加清晰,能够充分利用平板的较大屏幕空间,展示更多的信息和功能模块。在PC端,页面的排版更加大气,功能区域划分明确,用户可以同时进行多项操作,提高工作效率。例如,在一个项目管理系统中,PC端的任务列表页面可以同时展示任务名称、负责人、截止日期、进度等信息,用户可以方便地进行任务的筛选、排序和编辑操作。 4.2 前端开发技术 在前端开发技术上,FastAdmin借助RequireJS实现了JS模块的有效管理。RequireJS采用AMD(Asynchronous Module Definition)规范,能够根据页面的实际需求动态加载JS模块。例如,在一个复杂的电商商品详情页面中,当用户打开页面时,RequireJS会自动加载与商品展示相关的JS模块,如图片轮播效果的脚本、商品评论加载和显示的脚本等,而不会加载与当前页面无关的模块,如购物车结算模块的脚本,避免了不必要的资源浪费,提高了页面的加载速度。利用Less进行样式开发,让开发者能够更加高效地管理和维护样式。Less支持变量、混合、函数等特性,通过定义变量,可以轻松实现全局样式的统一修改。比如,将网站的主色调定义为一个变量,当需要更换网站的整体风格时,只需修改这个变量的值,所有使用该变量定义颜色的元素都会自动更新。使用混合可以复用常用的样式代码,减少代码冗余。例如,定义一个用于按钮样式的混合,包含按钮的背景颜色、边框样式、文字颜色等属性,在需要创建不同类型的按钮时,只需引用这个混合,即可快速生成按钮样式,无需重复编写相同的样式代码。函数则可以实现更加复杂的样式计算,如根据屏幕宽度动态调整元素的大小和位置。 五、强大的插件扩展功能 FastAdmin的插件扩展功能为开发者提供了无限的拓展空间。插件市场中汇聚了各种各样的插件,涵盖了功能扩展、界面美化、数据处理等多个方面。开发者可以根据项目的实际需求,在插件市场中快速找到并安装所需的插件。以一个在线医疗预约系统为例,为了实现患者在线支付挂号费用的功能,开发者可以在FastAdmin的插件市场中搜索并安装相关的支付插件,如微信支付插件或支付宝支付插件,无需从头开始开发支付功能,大大缩短了项目的开发周期。同时,FastAdmin支持插件的在线安装、卸载和升级,方便开发者对插件进行管理。当插件有新版本发布时,开发者可以直接在系统中进行升级,获取新的功能和性能优化。比如,某个数据统计插件发布了新版本,增加了更详细的数据分析图表类型和数据导出功能,开发者可以通过一键升级,快速将这些新功能应用到自己的项目中。 六、通用的会员模块和API模块 6.1 同一账号体系的权限验证 FastAdmin的通用会员模块和API模块,实现了Web端会员中心权限验证与API接口会员权限验证共用同一账号体系。这一设计不仅极大地提升了用户体验,也方便了开发者对用户信息的统一管理。用户只需在Web端注册一次账号,即可在使用API接口时直接登录,无需重复注册。例如,在一个集Web端应用和移动端APP于一体的社交平台中,用户在Web端注册并完善个人信息后,使用APP时可以直接使用同一账号登录,无需再次填写个人信息。对于开发者来说,统一的账号体系减少了开发和维护的工作量,避免了因账号体系不一致而导致的数据同步问题。同时,FastAdmin还提供了丰富的权限管理功能,开发者可以根据业务需求,为不同的用户角色设置不同的权限,确保用户只能访问和操作其被授权的功能和数据。 6.2 部署与多语言支持 在部署方面,FastAdmin支持二级域名部署,并且可以将域名绑定到应用插件。这为项目的部署和管理提供了更多的灵活性。例如,一个大型企业的多个业务模块可以分别部署在不同的二级域名下,方便用户访问和管理。如企业的电商业务可以部署在shop.example.com,而在线教育业务可以部署在edu.example.com。同时,FastAdmin还支持多语言,无论是服务端还是客户端,都能轻松切换语言。在国际化的项目中,用户可以根据自己的语言偏好选择对应的语言版本,提升了框架的通用性和用户满意度。比如,一个面向全球用户的旅游预订平台,用户可以在中文、英文、日文、韩文等多种语言版本之间自由切换,方便不同国家和地区的用户使用。 七、丰富的文件上传和表格功能 7.1 文件上传功能 FastAdmin在文件上传方面提供了多种便捷的方式。支持大文件分片上传,有效解决了大文件上传时容易出现的网络中断等问题。在上传大型视频文件或高清图片时,即使网络出现短暂波动,也能通过分片上传技术确保文件完整上传。例如,上传一个1GB的视频文件,FastAdmin会将其分成多个小块进行上传,当某个小块上传失败时,可以单独重新上传该小块,而无需重新上传整个文件。支持剪切板粘贴上传和拖拽上传,让用户的操作更加便捷高效。用户可以直接从其他应用程序中复制文件,然后粘贴到FastAdmin的文件上传区域,或者直接将文件从本地文件夹拖拽到上传区域。同时,在上传过程中还配有进度条显示,让用户实时了解上传进度。对于图片上传,FastAdmin还支持上传前压缩,有效减少了图片占用的存储空间,提高了上传速度。比如,一张原本5MB的高清图片,经过FastAdmin的压缩功能处理后,可能会压缩到几百KB,大大缩短了上传时间。 7.2 表格功能 在表格功能上,FastAdmin同样表现出色。支持表格固定列和固定表头,方便用户在查看大量数据时始终能够清晰地看到关键列和表头信息。在一个包含多个字段的财务报表中,用户可以将金额列和日期列固定,无论如何滚动表格,都能随时查看这些关键数据。支持跨页选择,用户可以在不同页面之间选择数据,进行统一处理。例如,在一个商品管理系统中,用户可以选择不同页面的商品进行批量下架操作。支持Excel导出,方便用户将表格数据导出到本地进行分析和处理。支持模板渲染,开发者可以根据实际需求自定义表格的显示样式和内容,满足了多样化的数据展示与处理需求。比如,在一个学生成绩管理系统中,开发者可以通过模板渲染,将学生的成绩按照不同的等级进行颜色区分显示,便于快速查看学生的成绩分布情况。 八、全面的第三方应用模块支持 8.1 内容管理与电商应用支持 FastAdmin对第三方应用模块的支持非常全面,涵盖了多个领域。在内容管理方面,支持CMS、博客、知识付费问答等应用,并且能够无缝整合Xunsearch全文搜索。以一个知识付费平台为例,用户可以通过Xunsearch快速搜索到自己感兴趣的知识内容,提高了内容的查找效率。在电商领域,支持B2C商城、B2B2C商城等,为电商项目的开发提供了强大的支持。在搭建B2C商城时,FastAdmin提供的各种电商相关功能和插件,如商品管理、订单处理、支付集成等,能够帮助开发者快速搭建出功能完善的电商平台。比如,通过FastAdmin的商品管理插件,开发者可以轻松实现商品的添加、编辑、分类管理、库存管理等功能;利用订单处理插件,可以对订单的状态进行跟踪、处理和统计分析;集成微信支付和支付宝支付插件,实现安全便捷的支付功能。 8.2 小程序与其他第三方服务支持 同时,FastAdmin还支持多种第三方小程序,如CMS小程序、预订小程序、问答小程序、点餐小程序、B2C小程序、B2B2C小程序、博客小程序等,帮助开发者快速实现小程序与Web端应用的互联互通。在一个餐饮企业中,通过FastAdmin开发的Web端管理系统和点餐小程序,用户可以在小程序上下单,商家则可以在Web端进行订单处理和菜品管理。此外,它还整合了阿里云、腾讯云短信等第三方短信接口,方便项目实现短信验证、通知等功能;整合了七牛云、阿里云OSS、又拍云等第三方云存储功能,且支持云储存分片上传,确保文件存储的安全性和高效性;支持Summernote、百度编辑器等第三方富文本编辑器,满足了不同用户对富文本编辑的需求;实现了QQ、微信、微博等第三方登录的整合,为用户提供了更加便捷的登录方式;以及微信、支付宝第三方支付的无缝整合,微信更是支持PC端扫码支付,为电商项目的支付功能提供了全面的解决方案。 九、丰富的插件应用市场 FastAdmin的插件应用市场是一个充满活力的开发生态。这里汇聚了来自全球各地开发者贡献的插件,涵盖了各种功能和应用场景。开发者可以在插件市场中通过搜索、分类筛选等方式快速找到所需的插件。插件市场不仅提供了插件的下载和安装功能,还为开发者提供了插件的详细介绍、使用说明和用户评价。开发者可以根据其他用户的评价和反馈,选择最适合自己项目的插件。同时,插件市场也鼓励开发者上传自己开发的插件,分享自己的开发成果,促进了开发者之间的交流与合作。例如,某个开发者开发了一个用于数据可视化的插件,将其上传到FastAdmin的插件市场后,其他开发者可以根据自己的需求下载使用,并在使用过程中提出改进建议,形成一个良性的循环。 十、安装使用与在线演示 10.1 安装使用指南 若您想深入了解和使用FastAdmin,可以通过访问https://doc.fastadmin.net 获取详细的安装指南和使用说明。这里提供了全面的文档,包括环境配置、安装步骤、功能使用教程等。无论您是新手开发者还是有经验的技术专家,都能在文档中找到所需的信息,快速上手FastAdmin。同时,为了方便您快速开启开发之旅,我们为您提供了FastAdmin的下载链接: 下载 fastadmin.zip 下载地址:https://www.123684.com/s/rCKrjv-eqb8d 提取码: 请根据提示进行下载和安装,如有任何疑问,可随时查阅官方文档。 10.2 在线演示体验 若您想先体验一下FastAdmin的功能,可登录在线演示地址:https://demo.fastadmin.net ,用户名:admin,密码:123456 。在演示站中,您可以直观地感受FastAdmin的各项功能和操作流程。不过需要注意的是,演示站数据无法进行修改,若您想要体验全部功能,建议下载源码安装,这样您可以根据自己的需求进行自由定制和扩展,充分发挥FastAdmin的强大功能。 结语 FastAdmin凭借其全面的功能、卓越的性能和丰富的扩展能力,为后台开发提供了一站式的解决方案。它不仅适用于企业级应用、电商平台、在线教育平台等大型项目的开发,也能满足小型项目和个人开发者的需求。无论您是追求开发效率的团队,还是渴望快速实现创意的个人开发者,FastAdmin都将是您的理想选择,助力您在软件开发的道路上乘风破浪,取得成功。
解锁高效开发新体验:极速后台开发框架FastAdmin FastAdmin:极速后台开发框架的全面解析 头图图片 前言 在当今软件开发的快节奏环境中,高效、稳定且功能强大的后台开发框架是开发者们梦寐以求的工具。一个优秀的框架不仅能大幅缩短开发周期,还能提升项目的整体质量和可维护性。FastAdmin,正是这样一款脱颖而出的基于ThinkPHP与Bootstrap深度融合的极速后台开发框架,它凭借丰富的特性和卓越的性能,在众多框架中占据了一席之地,深受开发者们的青睐。一、框架概述 FastAdmin的诞生,是技术融合与创新的结晶。ThinkPHP作为国内知名的PHP开发框架,以其简洁高效的代码风格、完善的MVC架构以及强大的数据库操作能力,为FastAdmin的后端开发筑牢根基。例如在处理复杂的业务逻辑和数据库交互时,ThinkPHP的Eloquent ORM(对象关系映射)功能,能让开发者以面向对象的方式轻松操作数据库,大大减少了SQL语句的编写量,提高了开发效率和代码的可读性。而Bootstrap,作为前端开发领域的佼佼者,以其简洁直观的设计理念、丰富多样的组件库以及出色的响应式布局,赋予了FastAdmin前端界面极高的美观度和用户友好性。无论是在大屏的PC端,还是小巧的手机屏幕上,FastAdmin的前端界面都能自适应,为用户提供一致且流畅的使用体验。 二、强大的权限管理系统 2.1 父子级权限继承 FastAdmin的权限管理系统依托于先进的Auth验证机制,为各类项目提供了精细化的权限控制方案。其中,无限层级的父子级权限继承功能尤为突出。想象一下,在一个大型连锁企业的管理系统中,企业总部的超级管理员作为顶级父级,拥有最高权限。他可以通过FastAdmin,为各个地区的区域经理分配不同的权限。比如,给予华东地区经理查看和修改该地区所有门店销售数据的权限,同时赋予其管理下属门店店长的权限。而门店店长作为子级,又可以进一步为店内的收银员、导购员等员工设置更为细致的操作权限,如收银员只能进行收款和退款操作,导购员只能查看商品库存和价格信息。这种层层递进的权限结构,确保了企业内部数据的安全流转和高效管理。 2.2 单管理员多角色模式 除了父子级权限继承,FastAdmin的单管理员多角色模式也为权限管理带来了极大的灵活性。以一个综合性的在线教育平台为例,平台的运营主管可能需要同时扮演课程管理员、学员管理专员和营销活动策划者等多个角色。在FastAdmin框架下,运营主管可以根据不同的业务场景,轻松切换角色。当进行课程管理时,切换到课程管理员角色,便拥有添加、编辑、删除课程以及设置课程价格和有效期等权限;在处理学员相关事务时,切换到学员管理专员角色,能够查看学员的学习进度、考试成绩,进行学员信息的修改和审核等操作;而在策划营销活动时,切换到营销活动策划者角色,可对活动的宣传文案、推广渠道等进行设置和管理。这种灵活的角色切换机制,避免了因权限限制而导致的工作流程繁琐问题,大大提高了管理员的工作效率。 2.3 数据管理权限 在数据管理方面,FastAdmin充分考虑了不同用户的实际需求。管理员既可以选择管理子级数据,从宏观层面掌控整个团队或组织的数据情况,以便进行数据分析和决策制定。例如在一个销售团队中,销售经理通过管理子级数据,可以查看每个销售人员的业绩报表,分析销售趋势,从而制定更合理的销售策略。也可以专注于个人数据的管理,确保个人负责的数据安全和隐私。比如,每个销售人员都可以对自己的客户信息进行单独管理,防止他人随意访问和修改,保护客户隐私。 三、卓越的一键生成功能 3.1 一键生成CRUD FastAdmin的一键生成CRUD功能,堪称开发过程中的“加速器”。在传统的项目开发中,创建控制器、模型、视图、JS、语言包、菜单以及回收站等基础模块,往往需要开发者耗费大量的时间和精力编写重复的代码。而FastAdmin的这一功能,极大地简化了开发流程。以一个简单的图书管理系统为例,开发者只需在FastAdmin的操作界面中,准确输入图书数据库表的结构信息,如书名、作者、出版社、出版日期等字段,以及相关的业务需求,如图书的添加、查询、借阅、归还等功能,然后轻轻点击一键生成按钮,系统便能在瞬间生成包含这些功能的完整CRUD代码。这不仅大大缩短了开发周期,还减少了因手动编写代码可能出现的错误,提高了代码的质量和一致性。 3.2 其他一键操作功能 除了一键生成CRUD,FastAdmin还提供了一系列便捷的一键操作功能,进一步提升了开发效率。一键压缩打包JS和CSS文件,能够有效优化前端资源的加载速度。在实际应用中,当项目上线后,大量分散的JS和CSS文件会增加浏览器的请求次数,从而延长页面的加载时间。通过FastAdmin的一键压缩打包功能,这些文件可以被合并成一个或几个文件,并进行压缩处理,减少了文件体积,加快了页面的加载速度,提升了用户体验。一键CDN静态资源部署功能,确保了项目的静态资源,如图片、样式文件和脚本文件等,能够在全球范围内快速分发。无论用户身处何地,都能迅速加载项目的相关资源,提高了应用的访问速度和稳定性。例如,对于一个面向全球用户的电商平台,通过CDN部署,欧洲的用户可以快速加载来自欧洲节点的静态资源,亚洲的用户则可以从亚洲节点获取,大大降低了网络延迟。一键生成控制器菜单和规则,使得菜单和权限规则的创建变得简单易懂。开发者只需按照系统提示,输入菜单名称、链接地址、所属模块等信息,即可快速创建出符合项目需求的菜单结构和对应的权限规则,避免了手动配置的繁琐和错误。一键生成API接口文档,为团队协作和接口对接提供了极大的便利。在多人协作开发项目中,清晰准确的API接口文档能够帮助不同的开发者快速了解接口的功能、参数要求和返回值格式,提高开发效率,减少因沟通不畅而导致的开发错误。 四、完善的前端功能组件开发 4.1 基于AdminLTE和Bootstrap的开发 FastAdmin的前端功能组件开发基于AdminLTE进行二次开发,充分汲取了AdminLTE简洁美观的设计风格和丰富实用的组件库。同时,以Bootstrap为基础,确保了前端界面的卓越响应式设计。在手机端,页面布局会自动适应屏幕尺寸,菜单通常会以折叠式的导航栏呈现,方便用户单手操作;按钮的大小和位置经过精心设计,便于用户点击。在平板端,页面的展示更加清晰,能够充分利用平板的较大屏幕空间,展示更多的信息和功能模块。在PC端,页面的排版更加大气,功能区域划分明确,用户可以同时进行多项操作,提高工作效率。例如,在一个项目管理系统中,PC端的任务列表页面可以同时展示任务名称、负责人、截止日期、进度等信息,用户可以方便地进行任务的筛选、排序和编辑操作。 4.2 前端开发技术 在前端开发技术上,FastAdmin借助RequireJS实现了JS模块的有效管理。RequireJS采用AMD(Asynchronous Module Definition)规范,能够根据页面的实际需求动态加载JS模块。例如,在一个复杂的电商商品详情页面中,当用户打开页面时,RequireJS会自动加载与商品展示相关的JS模块,如图片轮播效果的脚本、商品评论加载和显示的脚本等,而不会加载与当前页面无关的模块,如购物车结算模块的脚本,避免了不必要的资源浪费,提高了页面的加载速度。利用Less进行样式开发,让开发者能够更加高效地管理和维护样式。Less支持变量、混合、函数等特性,通过定义变量,可以轻松实现全局样式的统一修改。比如,将网站的主色调定义为一个变量,当需要更换网站的整体风格时,只需修改这个变量的值,所有使用该变量定义颜色的元素都会自动更新。使用混合可以复用常用的样式代码,减少代码冗余。例如,定义一个用于按钮样式的混合,包含按钮的背景颜色、边框样式、文字颜色等属性,在需要创建不同类型的按钮时,只需引用这个混合,即可快速生成按钮样式,无需重复编写相同的样式代码。函数则可以实现更加复杂的样式计算,如根据屏幕宽度动态调整元素的大小和位置。 五、强大的插件扩展功能 FastAdmin的插件扩展功能为开发者提供了无限的拓展空间。插件市场中汇聚了各种各样的插件,涵盖了功能扩展、界面美化、数据处理等多个方面。开发者可以根据项目的实际需求,在插件市场中快速找到并安装所需的插件。以一个在线医疗预约系统为例,为了实现患者在线支付挂号费用的功能,开发者可以在FastAdmin的插件市场中搜索并安装相关的支付插件,如微信支付插件或支付宝支付插件,无需从头开始开发支付功能,大大缩短了项目的开发周期。同时,FastAdmin支持插件的在线安装、卸载和升级,方便开发者对插件进行管理。当插件有新版本发布时,开发者可以直接在系统中进行升级,获取新的功能和性能优化。比如,某个数据统计插件发布了新版本,增加了更详细的数据分析图表类型和数据导出功能,开发者可以通过一键升级,快速将这些新功能应用到自己的项目中。 六、通用的会员模块和API模块 6.1 同一账号体系的权限验证 FastAdmin的通用会员模块和API模块,实现了Web端会员中心权限验证与API接口会员权限验证共用同一账号体系。这一设计不仅极大地提升了用户体验,也方便了开发者对用户信息的统一管理。用户只需在Web端注册一次账号,即可在使用API接口时直接登录,无需重复注册。例如,在一个集Web端应用和移动端APP于一体的社交平台中,用户在Web端注册并完善个人信息后,使用APP时可以直接使用同一账号登录,无需再次填写个人信息。对于开发者来说,统一的账号体系减少了开发和维护的工作量,避免了因账号体系不一致而导致的数据同步问题。同时,FastAdmin还提供了丰富的权限管理功能,开发者可以根据业务需求,为不同的用户角色设置不同的权限,确保用户只能访问和操作其被授权的功能和数据。 6.2 部署与多语言支持 在部署方面,FastAdmin支持二级域名部署,并且可以将域名绑定到应用插件。这为项目的部署和管理提供了更多的灵活性。例如,一个大型企业的多个业务模块可以分别部署在不同的二级域名下,方便用户访问和管理。如企业的电商业务可以部署在shop.example.com,而在线教育业务可以部署在edu.example.com。同时,FastAdmin还支持多语言,无论是服务端还是客户端,都能轻松切换语言。在国际化的项目中,用户可以根据自己的语言偏好选择对应的语言版本,提升了框架的通用性和用户满意度。比如,一个面向全球用户的旅游预订平台,用户可以在中文、英文、日文、韩文等多种语言版本之间自由切换,方便不同国家和地区的用户使用。 七、丰富的文件上传和表格功能 7.1 文件上传功能 FastAdmin在文件上传方面提供了多种便捷的方式。支持大文件分片上传,有效解决了大文件上传时容易出现的网络中断等问题。在上传大型视频文件或高清图片时,即使网络出现短暂波动,也能通过分片上传技术确保文件完整上传。例如,上传一个1GB的视频文件,FastAdmin会将其分成多个小块进行上传,当某个小块上传失败时,可以单独重新上传该小块,而无需重新上传整个文件。支持剪切板粘贴上传和拖拽上传,让用户的操作更加便捷高效。用户可以直接从其他应用程序中复制文件,然后粘贴到FastAdmin的文件上传区域,或者直接将文件从本地文件夹拖拽到上传区域。同时,在上传过程中还配有进度条显示,让用户实时了解上传进度。对于图片上传,FastAdmin还支持上传前压缩,有效减少了图片占用的存储空间,提高了上传速度。比如,一张原本5MB的高清图片,经过FastAdmin的压缩功能处理后,可能会压缩到几百KB,大大缩短了上传时间。 7.2 表格功能 在表格功能上,FastAdmin同样表现出色。支持表格固定列和固定表头,方便用户在查看大量数据时始终能够清晰地看到关键列和表头信息。在一个包含多个字段的财务报表中,用户可以将金额列和日期列固定,无论如何滚动表格,都能随时查看这些关键数据。支持跨页选择,用户可以在不同页面之间选择数据,进行统一处理。例如,在一个商品管理系统中,用户可以选择不同页面的商品进行批量下架操作。支持Excel导出,方便用户将表格数据导出到本地进行分析和处理。支持模板渲染,开发者可以根据实际需求自定义表格的显示样式和内容,满足了多样化的数据展示与处理需求。比如,在一个学生成绩管理系统中,开发者可以通过模板渲染,将学生的成绩按照不同的等级进行颜色区分显示,便于快速查看学生的成绩分布情况。 八、全面的第三方应用模块支持 8.1 内容管理与电商应用支持 FastAdmin对第三方应用模块的支持非常全面,涵盖了多个领域。在内容管理方面,支持CMS、博客、知识付费问答等应用,并且能够无缝整合Xunsearch全文搜索。以一个知识付费平台为例,用户可以通过Xunsearch快速搜索到自己感兴趣的知识内容,提高了内容的查找效率。在电商领域,支持B2C商城、B2B2C商城等,为电商项目的开发提供了强大的支持。在搭建B2C商城时,FastAdmin提供的各种电商相关功能和插件,如商品管理、订单处理、支付集成等,能够帮助开发者快速搭建出功能完善的电商平台。比如,通过FastAdmin的商品管理插件,开发者可以轻松实现商品的添加、编辑、分类管理、库存管理等功能;利用订单处理插件,可以对订单的状态进行跟踪、处理和统计分析;集成微信支付和支付宝支付插件,实现安全便捷的支付功能。 8.2 小程序与其他第三方服务支持 同时,FastAdmin还支持多种第三方小程序,如CMS小程序、预订小程序、问答小程序、点餐小程序、B2C小程序、B2B2C小程序、博客小程序等,帮助开发者快速实现小程序与Web端应用的互联互通。在一个餐饮企业中,通过FastAdmin开发的Web端管理系统和点餐小程序,用户可以在小程序上下单,商家则可以在Web端进行订单处理和菜品管理。此外,它还整合了阿里云、腾讯云短信等第三方短信接口,方便项目实现短信验证、通知等功能;整合了七牛云、阿里云OSS、又拍云等第三方云存储功能,且支持云储存分片上传,确保文件存储的安全性和高效性;支持Summernote、百度编辑器等第三方富文本编辑器,满足了不同用户对富文本编辑的需求;实现了QQ、微信、微博等第三方登录的整合,为用户提供了更加便捷的登录方式;以及微信、支付宝第三方支付的无缝整合,微信更是支持PC端扫码支付,为电商项目的支付功能提供了全面的解决方案。 九、丰富的插件应用市场 FastAdmin的插件应用市场是一个充满活力的开发生态。这里汇聚了来自全球各地开发者贡献的插件,涵盖了各种功能和应用场景。开发者可以在插件市场中通过搜索、分类筛选等方式快速找到所需的插件。插件市场不仅提供了插件的下载和安装功能,还为开发者提供了插件的详细介绍、使用说明和用户评价。开发者可以根据其他用户的评价和反馈,选择最适合自己项目的插件。同时,插件市场也鼓励开发者上传自己开发的插件,分享自己的开发成果,促进了开发者之间的交流与合作。例如,某个开发者开发了一个用于数据可视化的插件,将其上传到FastAdmin的插件市场后,其他开发者可以根据自己的需求下载使用,并在使用过程中提出改进建议,形成一个良性的循环。 十、安装使用与在线演示 10.1 安装使用指南 若您想深入了解和使用FastAdmin,可以通过访问https://doc.fastadmin.net 获取详细的安装指南和使用说明。这里提供了全面的文档,包括环境配置、安装步骤、功能使用教程等。无论您是新手开发者还是有经验的技术专家,都能在文档中找到所需的信息,快速上手FastAdmin。同时,为了方便您快速开启开发之旅,我们为您提供了FastAdmin的下载链接: 下载 fastadmin.zip 下载地址:https://www.123684.com/s/rCKrjv-eqb8d 提取码: 请根据提示进行下载和安装,如有任何疑问,可随时查阅官方文档。 10.2 在线演示体验 若您想先体验一下FastAdmin的功能,可登录在线演示地址:https://demo.fastadmin.net ,用户名:admin,密码:123456 。在演示站中,您可以直观地感受FastAdmin的各项功能和操作流程。不过需要注意的是,演示站数据无法进行修改,若您想要体验全部功能,建议下载源码安装,这样您可以根据自己的需求进行自由定制和扩展,充分发挥FastAdmin的强大功能。 结语 FastAdmin凭借其全面的功能、卓越的性能和丰富的扩展能力,为后台开发提供了一站式的解决方案。它不仅适用于企业级应用、电商平台、在线教育平台等大型项目的开发,也能满足小型项目和个人开发者的需求。无论您是追求开发效率的团队,还是渴望快速实现创意的个人开发者,FastAdmin都将是您的理想选择,助力您在软件开发的道路上乘风破浪,取得成功。
-
免费且可自部署的网站统计源码:Umami Umami——免费且可自部署的网站统计源码 头图图片 前言 在数字化信息爆炸的时代,网站已成为企业、组织和个人展示形象、传播信息、开展业务的重要窗口。对于网站运营者而言,深入了解用户行为、精准把握网站流量趋势,是优化网站性能、提升用户体验、实现业务增长的关键。而这一切,都离不开强大且精准的网站统计工具。一款优秀的网站统计工具,不仅能记录网站的访问量、访客来源等基础数据,还能深入分析用户的行为路径、偏好习惯,为运营决策提供有力的数据支持。Umami,正是这样一款在网站统计领域崭露头角的开源工具。它基于Node.js开发,以其免费且可自部署的特性,为广大网站运营者和开发者提供了高度定制化的统计解决方案。接下来,让我们深入探究Umami的源码特性、部署流程以及其在实际应用中的强大功能。 Umami源码介绍 Umami是一款基于Node.js开发的开源网站统计程序,其源码托管于GitHub,以高度的透明度和开放性,吸引了全球开发者的关注与参与 。从技术架构上看,它采用了现代Web开发中流行的前后端分离模式。前端部分主要运用了Vue.js框架,构建出简洁直观且交互性强的用户界面,为用户提供流畅的数据可视化展示和便捷的操作体验,无论是查看实时流量数据,还是进行深度的数据过滤分析,都能轻松实现。后端则依托Node.js的高效I/O处理能力,搭配Express框架搭建服务器,负责处理数据的接收、存储和接口调用,确保数据处理的高效性和稳定性。 在数据存储方面,Umami支持多种数据库,其中以PostgreSQL的兼容性最佳。这使得它能够借助PostgreSQL强大的事务处理和数据管理能力,可靠地存储和管理大量的网站统计数据。其源码中的数据采集模块设计精巧,通过在网站页面嵌入轻量级的JavaScript代码,能够精准地捕捉用户的各类行为数据,如页面浏览、点击事件、滚动操作等,并且以高效的方式将这些数据传输回服务器进行分析处理 。 Umami的开源性质不仅为开发者提供了学习和定制的机会,还促进了社区的繁荣发展。开发者可以根据自身需求,对源码进行二次开发,扩展功能或优化性能。同时,社区成员之间的交流与协作,不断推动着Umami的持续更新和完善,使其始终保持在网站统计领域的前沿地位,为众多网站提供专业、可靠的统计分析服务。 下载 umami-master.zip 下载地址:https://www.123684.com/s/rCKrjv-Y5b8d 提取码: Umami部署具体步骤 服务器环境准备 系统选型与适配:在部署Umami之前,需根据实际需求和服务器硬件条件审慎选择Linux发行版。Ubuntu因其拥有极为丰富的软件仓库,涵盖各类前沿开发工具与技术框架,成为新手用户踏入服务器部署领域的理想选择。在进行Ubuntu Server安装时,通过图形化安装界面,用户能够依据自身业务对数据存储和读写的需求,精准地对磁盘进行分区规划。例如,考虑到Umami在运行过程中会产生大量的日志数据以及频繁读写统计数据,可将用于存储动态数据的/var目录分配较大的磁盘空间,从而确保系统在高负载的数据存储与读取操作下,依然能够保持高效稳定的运行状态。 CentOS则凭借其在企业级应用中久经考验的稳定性以及长期的技术支持,成为追求系统可靠性和稳定性的企业用户的首选。在安装CentOS时,经验丰富的系统管理员可根据服务器硬件配置,深入操作系统内核层面,对诸如内存分配算法、进程调度策略等关键内核参数进行精细调整。以内存分配为例,通过优化内存分配算法,可使系统在高并发访问的复杂场景下,更合理地分配内存资源,避免因内存不足或分配不合理导致的系统性能下降,为Umami的稳定运行提供坚实可靠的系统基础。 Node.js与npm的安装与调试:Node.js基于Chrome V8引擎构建,为JavaScript在服务器端的高效运行提供了强大的运行时环境,是Umami实现其丰富功能的核心依赖。在Ubuntu系统中,利用apt包管理器进行安装时,首先执行sudo apt update命令,此命令的作用是与远程软件源建立通信,获取最新的软件包元数据,确保后续安装的Node.js版本为最新且包含最新的安全补丁和功能特性。随后执行npm install命令,npm会依据项目package.json文件中定义的依赖关系树,递归地从npm仓库下载并安装项目运行所需的所有依赖包。 在实际安装过程中,依赖冲突是较为常见且棘手的问题。当两个或多个不同的包依赖同一模块的不同版本时,就可能引发依赖冲突。例如,包A依赖模块X的1.0版本,而包B依赖模块X的2.0版本,这种情况下直接安装可能导致模块版本不一致,从而引发运行时错误。此时,若使用npm install --force命令强制安装,虽然可能暂时解决安装问题,但可能会破坏依赖的完整性,导致在运行过程中出现难以排查的错误。更为稳妥的解决方案是,深入查阅官方文档,了解各个依赖包的版本兼容性说明,或者在专业的技术社区论坛上搜索相关解决方案,通过手动调整package.json文件中的依赖包版本号,尝试找到一个兼容的版本组合,确保安装过程顺利且依赖关系稳定可靠。 数据库安装与初始化(以PostgreSQL为例):PostgreSQL作为一款功能强大、高度可靠的开源关系型数据库,以其卓越的事务处理能力和对丰富数据类型的广泛支持,成为存储Umami统计数据的绝佳选择。在Ubuntu系统上安装时,执行sudo apt install postgresql postgresql - contrib命令,该命令不仅会安装PostgreSQL数据库的核心组件,还会一并安装一系列常用的扩展包,这些扩展包为后续的数据库管理、数据处理以及功能拓展提供了丰富的工具和功能支持。 安装完成后,进入psql控制台,使用CREATE ROLE命令创建新角色,如CREATE ROLE umami_user WITH LOGIN PASSWORD'secure_password';。在设置密码时,务必遵循高强度密码原则,密码应包含大小写字母、数字和特殊字符,长度不少于8位,以有效抵御暴力破解等安全攻击手段,保障数据库用户的账户安全。接着,通过CREATE DATABASE命令创建数据库,如CREATE DATABASE umami_db OWNER umami_user;,明确指定数据库所有者为刚创建的用户,这样细致的权限设置和数据库创建过程,为Umami准确记录和高效管理网站统计数据构建了一个安全、稳定且高效的数据库环境。 下载并安装Umami 代码克隆与网络依赖:通过SSH安全连接到服务器后,选择/var/www/umami作为项目目录,这一选择遵循了Web应用程序的常规部署路径规范,便于对项目进行统一管理、维护以及权限控制。使用git clone命令从GitHub克隆代码时,网络稳定性是影响克隆过程的关键因素。若网络不稳定,可能导致克隆过程中断,出现诸如“Connection reset by peer”或“RPC failed; curl 56 GnuTLS recv error (-110): The TLS connection was non-properly terminated.”等错误提示。 此时,用户可以通过执行git config --global http.lowSpeedLimit 0和git config --global http.lowSpeedTime 999999命令,调整Git的网络传输设置,将低速传输限制设置为0,即不限制传输速度,同时延长低速传输的时间限制,避免因网络低速传输而导致克隆失败。此外,还需仔细检查网络连接是否存在防火墙限制,确保服务器能够正常访问GitHub代码仓库。若服务器处于企业内部网络环境,可能需要配置代理服务器,通过执行git config --global http.proxy http://proxy.example.com:port和git config --global https.proxy https://proxy.example.com:port命令,设置正确的代理服务器地址和端口,以确保能够顺利从GitHub获取代码。 依赖安装与问题排查:进入项目目录后执行npm install命令,npm会从远程仓库下载依赖包,并解压到node_modules目录。在这个过程中,若依赖包下载失败,除了常规的清除缓存重新下载操作,即执行npm cache clean --force命令后再重新安装,还需要深入检查本地网络代理设置。如果服务器处于特定的网络环境,如企业内部网络或使用了代理服务器,可能需要配置正确的代理服务器地址和端口。可以通过执行npm config set proxy http://proxy.example.com:port和npm config set https-proxy https://proxy.example.com:port命令,设置npm的代理服务器。 对于版本不兼容问题,使用npm list命令可以查看已安装依赖的版本树,清晰地展示各个依赖包及其版本信息。通过手动调整package.json文件中的版本号,再重新执行安装命令,尝试解决版本冲突问题。同时,参考依赖包的官方文档和社区讨论,获取关于版本兼容性的最新信息,也是解决问题的有效途径。例如,某些依赖包在特定的Node.js版本下可能存在兼容性问题,通过查阅官方文档了解到需要升级或降级Node.js版本,从而解决依赖不兼容的问题。 配置Umami 配置文件的复制与安全考量:将.env.example文件复制为.env文件,这一操作看似简单,却在Umami的部署过程中具有重要的安全和配置灵活性意义。.env文件中的环境变量决定了Umami的运行参数,其中数据库连接配置尤为关键。DB_HOST、DB_PORT、DB_USER、DB_PASSWORD和DB_DATABASE等参数必须与PostgreSQL中创建的数据库和用户信息精确匹配,任何一个参数的错误都可能导致Umami无法正常连接数据库。 在设置管理员账号密码时,为了增强系统的安全性,强烈建议使用专业的强密码生成工具,如openssl rand -base64 32命令,生成高强度的随机密码。这样生成的密码由32个经过Base64编码的随机字符组成,包含大小写字母、数字和特殊字符,极大地增加了密码的复杂度和安全性,有效防止了恶意攻击者通过猜测密码获取系统权限。 精细配置与错误防范:配置文件中的每一个参数都直接影响着Umami的运行状态。若DB_PASSWORD填写错误,Umami在启动时将无法连接数据库,此时控制台会输出详细的连接错误信息,如Connection refused表示无法连接到数据库服务器,可能是由于服务器地址错误、端口被占用或防火墙限制;Authentication failed则表示认证失败,即用户名或密码错误。面对此类问题,用户需要仔细核对配置文件中的密码,确保准确无误。同时,检查数据库用户权限,在psql控制台中使用\du命令查看用户权限,确保该用户具备连接和操作数据库的所有必要权限,包括CONNECT权限用于连接数据库,CREATE权限用于创建表、视图等数据库对象,INSERT、UPDATE、DELETE和SELECT权限用于对数据进行增删改查操作。若权限不足,可使用GRANT命令赋予相应权限,如GRANT ALL PRIVILEGES ON DATABASE umami_db TO umami_user;,确保Umami能够顺利连接数据库并正常运行。 初始化数据库:执行npx umami db:create命令,该命令会依据配置文件中的数据库信息,在PostgreSQL中创建一系列表结构,这些表结构专门用于存储网站统计数据,包括用户的访问记录,详细记录用户的访问时间、来源IP、访问页面路径等信息;行为分析数据,如用户在页面上的停留时间、点击行为、滚动行为等;以及自定义事件数据,根据用户在网站上设置的自定义事件,记录事件的触发时间、触发条件、相关参数等数据。 若初始化过程失败并提示权限不足,用户可在psql控制台中使用GRANT ALL PRIVILEGES ON DATABASE umami_db TO umami_user;命令,赋予用户足够的权限,确保其能够创建表结构。若出现数据库连接错误,首先检查配置文件中的连接参数,确认DB_HOST、DB_PORT、DB_USER和DB_PASSWORD等参数是否正确。同时,使用ping命令检查数据库服务器的网络连通性,确保数据库服务器正常运行且网络可达。若网络连通性存在问题,可通过检查网络配置、路由器设置、防火墙规则等,排查并解决网络故障。 启动Umami 项目构建与错误处理:执行npm run build命令,这一过程中,Webpack等构建工具会对源代码进行全面的编译、压缩和优化。如果源代码中存在语法错误,例如JavaScript文件中的语法错误,构建工具会在控制台输出详细的错误位置和错误信息,如SyntaxError: Unexpected token并指出具体的行号和列号。开发者需要根据这些提示,仔细检查并修改源代码,确保语法正确后重新构建。 若出现依赖缺失问题,可通过npm install命令重新安装缺失的依赖包。在重新安装之前,也可以先查看package.json文件,确认依赖包的版本和名称是否正确,避免因错误的依赖配置导致安装失败。此外,还需注意依赖包之间的相互关系,某些依赖包可能需要特定的环境变量或其他依赖包的支持才能正常安装和运行。例如,某些依赖包可能依赖于系统中的特定库文件,此时需要确保系统中已安装相应的库文件,并正确设置相关的环境变量。 服务启动与访问调试:执行npm start命令启动Umami服务,若无法访问,端口被占用是常见的原因之一。使用lsof -i :3000命令可以查看占用3000端口(默认端口)的进程信息,若发现该端口被其他程序占用,用户可以修改Umami配置文件中的端口号,如将其修改为3001,然后重新启动服务。同时,检查服务器的防火墙设置,确保允许外部访问指定端口。以Ubuntu的UFW防火墙为例,使用ufw allow 3000/tcp命令开放3000端口,确保Umami服务能够正常接受外部请求。 此外,还可以检查服务器的日志文件,查看是否有其他错误信息,如服务启动过程中的异常报错。在Linux系统中,通常可以在/var/log目录下找到相关的日志文件,如npm-debug.log记录了npm运行过程中的详细信息,umami.log记录了Umami服务的运行日志。通过分析这些日志文件,能够更准确地定位问题所在,如是否存在依赖包加载失败、配置文件读取错误等问题,以便及时排查问题,确保Umami服务能够稳定、正常地运行。 结语 综上所述,Umami凭借其开源的特性、先进的技术架构、丰富的功能以及相对简便的部署流程,为网站统计分析提供了一个极具价值的解决方案。无论是小型个人网站,还是大型企业级网站,都能从Umami的精准数据统计和深入分析中获益。随着互联网技术的不断发展,网站运营对于数据的依赖程度日益加深,相信Umami在未来将不断演进,持续为广大网站运营者提供更强大、更智能的统计服务,助力网站在激烈的网络竞争中脱颖而出,实现可持续发展。
-
一键搭建!IPTV电视直播源管理系统源码,超简单部署教程 一键搭建!IPTV电视直播源管理系统源码,超简单部署教程 头图图片 前言 在如今数字浪潮的时代,传统电视直播模式已无法满足大众日益多元化的需求。人们对个性化、定制化电视直播体验的渴望愈发强烈,IPTV电视直播源管理系统源码应运而生。它如同开启专属电视直播软件大门的钥匙,让用户能够掌控独特的直播体验。系统介绍 这套系统源码的核心在于与定制的DIYP影音无缝对接,构建高度定制化的电视直播软件。其灵感源于恩山无线论坛的《IPTV管理系统》,开发者在使用中发现部分功能不便,凭借技术功底和创新精神,基于DIYP软件接口打造了全新的后台管理系统。需注意,该项目为纯粹管理系统,自身无直播源,却为用户提供了广阔的自主拓展空间,用户可按需自由添加、管理直播源。 部署教程 接下来,为大家详细介绍系统的部署与设置步骤,助你顺利搭建电视直播管理后台。 后台部署 准备工作:系统源码在下方,需安装python环境。Python作为功能强大、应用广泛的编程语言,是系统稳定运行的关键。初次接触python环境安装的朋友不必担忧,互联网上有海量详细教程,从基础概念到实际操作步骤,即使是编程新手,按步骤操作也能顺利完成。以Windows系统为例,先访问Python官方网站(https://www.python.org/downloads/ ),依据系统版本(32位或64位)精准选择安装包下载。下载完成后,双击安装包启动程序,务必勾选“Add Python to PATH”选项,以便后续在命令行中直接调用Python命令,提高操作效率。 IPTV 电视直播源管理系统源码 下载地址:https://www.123684.com/s/rCKrjv-dcb8d 提取码: 安装基本库:python环境安装完成后,进入安装基本库的关键环节。在命令行准确执行代码:pip install -r requirements.txt 。此步骤如同为系统组装“零部件”,这些基本库协同工作,是确保系统各项功能正常运行的核心。执行命令时,确保网络连接稳定,否则可能导致安装失败。执行命令后,pip工具读取requirements.txt文件内容,该文件详细列出系统运行依赖的库及版本信息,pip据此从Python Package Index(PyPI)等软件源下载并安装相应库。安装过程中,可在命令行界面实时查看进度和提示信息。若遇库安装失败,原因可能是网络波动、软件源故障或依赖冲突等,此时可尝试更换软件源,如国内的清华源、阿里云源,操作方法为在命令行临时使用指定源安装,例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt 。 启动系统:基本库安装成功后,打开源代码目录,执行启动命令:python manage.py runserver 0.0.0.0:8000 。“0.0.0.0:8000”表示将服务器绑定到本地所有可用网络接口(0.0.0.0代表所有接口)并监听8000端口。执行命令后,若系统无报错,会看到命令行输出类似“Starting development server at http://0.0.0.0:8000/”的信息,表明系统已成功启动,等待用户访问和操作。 登录后台:在浏览器地址栏输入127.0.0.1:8000/admin/login ,打开登录页面。输入正确账号和密码(首次使用需按说明设置或获取初始账号密码)即可登录系统后台。需注意,项目中的apk和readmeimg文件夹并非项目运行必需,部署时可不包含,以简化部署流程、提高效率。登录时若遇密码错误提示,先检查是否开启大写锁定键,也可尝试通过找回密码功能(若系统提供)重置密码。若页面无法正常加载,可能是服务器未成功启动、端口被占用等原因,可在命令行查看服务器启动日志,根据错误信息排查问题。 后台密码相关事项 在使用IPTV电视直播源管理系统时,后台密码的设置与管理至关重要。若遇后台密码错误,可尝试在数据库中修改。 数据库修改MD5:数据库中存在多种MD5加密后的密码示例,以下是常见的MD5值及其对应密码(均为123456): 14e1b600b1fd579f47433b88e8d85291 密码:123456 e10adc3949ba59abbe56e057f20f883e 密码:123456 eeafb716f93fa090d7716749a6eefa72 密码:123456 e120dae791fe8c7b5652f8933078b3ee 密码:123456 f1bca3e796587ea13d805cf1cd5cf112 密码:123456 9471563eb1136fd2a934867a1983bbc3 密码:123456 c642OOS9H94QeM0LTftIi5eAzhE4JxI+vyPOh05K6bXikXY 密码:123456 $2y$10$6jyzWTNtTdMvYabho.WCbemnH9f6SJGAoUMH0TNVwyHiW6J0nG6aS 密码:123456 $2y$10$EJ64ugc3YEnGH2jaM06XCO68igbTx4LpkcfVPnzoJHRy8Wm8h0Hti 密码:123456($2k类型用这个) 遇到后台密码错误时,可按上述MD5值逐个在数据库中试用替换。若仍无法解决,可参考以下情况。 其他常见数据库密码格式:后台数据库中还存在以下不同格式的密码相关记录及其对应密码(均为123456): 后台数据库里替换md5的值为 adc3949ba59abbe56e057f20f8,后台账号 密码 admin 123456 后台数据库里是这种170bdaa40e01eb1be2dbbf318c5e9111,密码:123456 后台数据库里是这种6e20b1394f05e1f9188ffff90147b4eb,密码:123456 后台数据库里是这种ed696eb5bba1f7460585cc6975e6cf9bf24903dd,密码:123456 后台数据库里是这种4dc7klUgD23hwvA4MtukDFr99gVxw7SRs9gEwUitnicCbgU,密码:123456 后台数据库里是这种4ddf64e9830520d68963368bc970afa2,密码:123456 加盐MD5密码:除普通MD5加密,还有加盐MD5密码情况,例如:c13f62012fd6a8fdf06b3452a94430e5 密码:123456 ,盐:rpR6Bv。处理加盐MD5密码时,需同时考虑盐值和MD5值对应关系。 代码层面修改加密方式(以MD5为例):若需在代码层面将密码加密方式改为MD5(虽MD5算法存在安全风险,后文详述),可按以下操作。在代码中找到与密码加密相关部分,通常与用户登录验证功能模块相关。以PHP代码为例,将$hash_algorithm改为’md5’,代码如下: $password = $_POST['password']; // 从HTTP POST请求中获取用户输入的密码 $hashed_password = md5($password); // 使用MD5算法对获取到的密码进行加密处理,生成加密后的哈希值完成代码修改后,保存源代码文件,重新部署应用程序。部署完成后,使用新密码进行登录测试,观察登录过程是否顺畅,确保密码修改生效。 密码加密方式的安全性考量 需提醒的是,MD5算法已不建议使用,因其存在安全漏洞,随着计算机技术发展,加密后的哈希值易被破解,存在系统安全风险。更安全的方式是使用加盐的哈希算法,如bcrypt或scrypt。bcrypt算法增加随机盐值和自适应工作因子,可有效抵御暴力破解和彩虹表攻击;scrypt算法引入内存硬函数,破解密码需消耗大量内存资源,提高了密码安全性。 密码问题的进一步排查 若按上述方法仍无法解决后台密码问题,可在全局文件中搜索关键词:password,定位与密码相关的代码片段,仔细检查是否存在逻辑错误或影响密码验证的因素。修改代码时务必谨慎,提前备份原始代码,避免错误修改导致系统出现更严重问题。检查时逐行分析密码的获取、加密、比对等环节,注意变量的作用域、数据类型等细节,通过细致排查和修改,有望解决密码相关疑难问题。 DIYP设置 软件修改:打开apk文件夹下的DIYP修改版.apk,借助MT管理器或类似文件管理器操作。以MT管理器为例,打开后在文件列表中找到apk文件路径,长按选择“打开方式”为MT管理器打开。进入apk文件内部,找到classes.dex文件,在其中搜索“10.0.0.1:1234”,此为默认服务器地址和端口,需替换为自己服务器的实际地址和端口。在MT管理器中点击右上角放大镜图标进入搜索界面,输入“10.0.0.1:1234”搜索,找到后长按选中内容,选择“编辑”进行修改,修改完成后点击保存按钮确保生效。此步骤决定软件能否正确连接服务器,实现数据交互和直播功能,替换完成后保存修改并退出文件管理器。 安装与拓展:完成修改后可直接安装DIYP软件。技术能力较强的用户可对软件进一步优化拓展,如更换软件图标,需提前准备符合尺寸要求的图片素材,可自行设计或从网络获取,使用apktool等工具解包apk文件,找到存放图标的资源文件夹,替换原图标后重新打包签名,确保软件正常安装运行;也可调整加密方式增强软件安全性,但此操作涉及专业密码学知识和编程技能,需谨慎操作,避免破坏软件正常功能;还可优化播放方法,从网络请求优化、视频解码算法调整等方面入手,分析软件播放流程和性能瓶颈,有针对性地修改优化代码,提升直播播放的流畅度和稳定性。 结语 IPTV电视直播源管理系统源码为用户和开发者提供了个性化电视直播的可能,无论是追求独特体验的普通用户,还是热衷技术探索的开发者,都能从中挖掘无限潜力,开启个性化直播新征程。若你对打造个性化电视直播软件感兴趣,不妨按上述步骤尝试,相信会收获惊喜。
-
福利源码发布页HTML导航页源码:助力打造个性化引导页 福利源码发布页:HTML 导航页源码助力便捷访问多网站 https://www.helloimg.com/i/2025/02/10/67a9c97a757c0.png图片 一、引言 如何才能拥有一个高效、美观且实用的导航工具,成为了许多人关注的焦点。因为咱爱好者,不可能只搞一个网站,一般365行,行行搞一点。这时就需要一个页面来聚合网站在一起,为用户提供引导。 今天,我们就为大家带来一款精心设计的福利源码发布页的 HTML 导航页源码。它不仅是一个简单的网页导航,更是帮助多网站站长更方便地聚合自己的所有网站。通过简洁直观的界面设计、出色的视觉效果和流畅的交互体验,轻松查看你的所有网站 二、源码呈现 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>福利源码|发布页</title> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.2/css/all.min.css"> <style> /* 全局样式 */ body { font-family: 'Inter', sans-serif; background: linear-gradient(45deg, #00F260 0%, #0575E6 100%); margin: 0; padding: 0; display: flex; justify-content: center; align-items: center; min-height: 100vh; perspective: 1000px; } /* 容器样式 */ .container { background: rgba(255, 255, 255, 0.1); backdrop-filter: blur(20px); -webkit-backdrop-filter: blur(20px); padding: 40px; border-radius: 25px; border: 1px solid rgba(255, 255, 255, 0.2); box-shadow: 0 15px 35px rgba(0, 0, 0, 0.1); width: 600px; text-align: center; transform-style: preserve-3d; animation: fadeInUp 0.8s ease-out; } @keyframes fadeInUp { from { opacity: 0; transform: translate3d(0, 80px, 0); } to { opacity: 1; transform: translate3d(0, 0, 0); } } /* 标题样式 */ h1 { color: #fff; font-size: 42px; margin-bottom: 30px; text-shadow: 0 4px 8px rgba(0, 0, 0, 0.2); letter-spacing: 1px; } /* 列表样式 */ ul { list-style-type: none; padding: 0; } li { margin-bottom: 25px; } /* 链接样式 */ a { display: flex; align-items: center; justify-content: center; padding: 20px; background: linear-gradient(45deg, #FF512F 0%, #F09819 100%); color: white; font-size: 22px; font-weight: 600; text-align: center; text-decoration: none; border-radius: 15px; transition: all 0.3s ease; box-shadow: 0 8px 16px rgba(0, 0, 0, 0.15); } a i { margin-right: 15px; font-size: 28px; } a:hover { transform: translateY(-7px) rotateX(10deg); box-shadow: 0 12px 24px rgba(0, 0, 0, 0.25); background: linear-gradient(45deg, #F09819 0%, #FF512F 100%); } </style> </head> <body> <div class="container"> <h1>最新网址</h1> <ul> <li><a href="https://www.fulicode.cn" target="_blank"><i class="fa-solid fa-code"></i>福利源码官网入口 1</a></li> <li><a href="https://www.fulicode.cn" target="_blank"><i class="fa-solid fa-code"></i>福利源码官网入口 2</a></li> <li><a href="https://www.fulicode.cn" target="_blank"><i class="fa-solid fa-code"></i>福利源码官网入口 3</a></li> <li><a href="https://www.fulicode.cn" target="_blank"><i class="fa-solid fa-code"></i>福利源码官网入口 4</a></li> <li><a href="https://www.fulicode.cn" target="_blank"><i class="fa-solid fa-code"></i>福利源码官网入口 5</a></li> </ul> </div> </body> </html>三、源码深度剖析 (一)HTML 结构解析 HTML 部分作为整个导航页的基石,构建起了页面的基本框架,犹如建筑师精心绘制的蓝图,为后续的设计和实现奠定了坚实的基础。 在文档的起始处,<!DOCTYPE html> 这一简洁的声明,明确地向浏览器传达了这是一个遵循 HTML5 标准的文档,确保浏览器能够以正确的模式对页面进行解析和渲染。<html> 标签作为整个 HTML 文档的根元素,承载着所有的页面内容,而 lang="zh-CN" 属性则贴心地指定了文档所使用的语言为中文,方便了国内用户的浏览和使用。 <head> 标签内部包含了一系列至关重要的元数据,这些元数据虽然在页面上不可见,但却对页面的正常显示和搜索引擎优化起着关键作用。meta 标签中的 charset="UTF-8" 属性,确保了页面能够正确地显示各种字符,特别是中文等特殊字符,避免了因字符编码问题而导致的乱码现象,为用户提供了流畅的阅读体验。而 name="viewport" 标签则是为了适应不同设备的屏幕尺寸而设置的,它通过 content="width=device-width, initial-scale=1.0" 让页面能够根据设备的屏幕宽度进行自适应调整,保证了在各种移动设备和桌面设备上都能完美显示,为用户带来一致的视觉感受。 页面标题 <title>福利源码|发布页</title> 简洁明了地概括了页面的核心主题(当然你可以改他),不仅让用户在浏览浏览器标签时能够快速识别页面内容,同时也为搜索引擎提供了重要的关键词信息,有助于提高页面在搜索结果中的排名。此外,通过 <link> 标签引入的 Font Awesome 图标库,为页面增添了丰富而精美的图标元素。这些图标不仅能够增强页面的视觉吸引力,还能直观地传达链接的含义,使用户能够更快速地理解和操作。 进入到 <body> 标签,这里是页面实际内容的展示区域。一个类名为 container 的 <div> 元素成为了整个导航页的核心容器,它将标题和链接列表紧密地包裹在一起,形成了一个有机的整体。标题 <h1>最新网址</h1> 以醒目的字体和较大的字号出现在页面上方,清晰地向用户提示了该导航页的主要功能,即提供多个网站的最新访问地址。链接列表则使用无序列表 <ul> 和列表项 <li> 进行构建,每个列表项中都包含一个 <a> 标签,用于创建指向目标网站的链接。target="_blank" 属性的设置非常贴心,它使得用户在点击链接时,页面会在新的窗口中打开,这样既不会打断用户当前的浏览进程,又能方便用户快速访问你的多个网站,提升了用户的操作体验。 (二)CSS 样式解读 全局样式设计 body 标签的样式设置为整个页面营造了一个独特而舒适的视觉环境,就像为整个舞台布置了精美的背景。字体方面,选择了 'Inter', sans-serif 这种现代感十足的无衬线字体。这种字体不仅具有简洁、流畅的外观,而且在不同的设备和屏幕分辨率下都能保持良好的可读性,确保用户能够轻松地阅读页面上的文字内容。 背景部分采用了绚丽的渐变效果 linear-gradient(45deg, #00F260 0%, #0575E6 100%),从清新的绿色逐渐过渡到深邃的蓝色,仿佛一幅美丽的画卷在眼前徐徐展开。这种渐变背景不仅营造出了一种充满科技感和未来感的氛围,还能给用户带来视觉上的享受,使整个页面更加生动和吸引人。 通过 Flexbox 布局技术,即 display: flex、justify-content: center 和 align-items: center 的组合使用,页面内容被巧妙地垂直和水平居中显示。这使得页面布局更加规整、对称,给人一种简洁、大气的感觉。同时,perspective: 1000px 属性的设置为页面添加了 3D 视角,为后续的动画效果埋下了伏笔,让页面在静态展示的基础上增添了一份动态的魅力。 容器样式打造 .container 类定义了导航页容器的样式,它就像一个精致的盒子,将页面的核心内容精心地包裹起来。半透明背景 rgba(255, 255, 255, 0.1) 与 backdrop-filter: blur(20px) 属性相结合,实现了令人惊艳的毛玻璃效果。这种效果使得容器仿佛悬浮在页面之上,与背景形成了一种若即若离的朦胧美感,增添了一份神秘和高级感。为了确保在 Safari 浏览器中也能正常显示该效果,还添加了 -webkit-backdrop-filter: blur(20px) 这一兼容性属性。 容器的内边距设置为 40px,为内部的标题和链接列表提供了足够的空间,避免了内容过于拥挤,使页面看起来更加清爽、舒适。border-radius: 25px 属性让容器的边角变得更加圆润,给人一种柔和、亲切的视觉感受,与整个页面的设计风格相得益彰。border: 1px solid rgba(255, 255, 255, 0.2) 为容器添加了一层淡淡的白色边框,这层边框虽然看似细微,但却起到了增强层次感的重要作用,使容器在背景的衬托下更加突出。 box-shadow: 0 15px 35px rgba(0, 0, 0, 0.1) 为容器添加了恰到好处的阴影效果,使其看起来更加立体,仿佛从页面中“浮”了起来。transform-style: preserve-3d 属性与之前 body 标签中的 perspective 属性相互配合,确保了 3D 效果能够在容器及其子元素上正常显示。而 animation: fadeInUp 0.8s ease-out 则为容器添加了一个淡入向上的动画效果。当页面加载时,容器会从下方缓缓升起并逐渐显示出来,就像舞台上的幕布缓缓拉开,为用户带来了一种惊喜和期待的感觉,大大提升了页面的视觉体验。 标题样式雕琢 h1 标签的样式设计着重突出了标题的重要性,使其成为页面上的视觉焦点。字体颜色设置为纯净的白色 #fff,与背景的渐变颜色形成了鲜明的对比,让标题在页面上格外醒目,能够迅速吸引用户的注意力。font-size: 42px 进一步增大了标题的字体大小,使其更加大气、庄重,彰显出福利源码发布页的权威性和专业性。 text-shadow: 0 4px 8px rgba(0, 0, 0, 0.2) 为标题添加了细腻的文字阴影效果。这层阴影不仅增强了标题的立体感和层次感,还使其在视觉上更加生动、鲜活,仿佛具有一种“跃然纸上”的感觉。letter-spacing: 1px 属性增加了字母之间的间距,使标题文字更加舒展、开阔,避免了文字过于紧凑而产生的压抑感,提升了整体的美观度和可读性。 链接样式优化 链接部分的样式设计充分考虑了用户的交互体验,力求让用户在操作过程中感受到便捷和愉悦。<a> 标签采用了 Flexbox 布局,通过 display: flex、align-items: center 和 justify-content: center 的设置,使得图标和文字能够完美地垂直和水平居中对齐。这种布局方式不仅保证了视觉上的一致性和整齐性,还让链接在不同的屏幕尺寸下都能保持良好的显示效果。 背景方面,链接使用了橙红色渐变 linear-gradient(45deg, #FF512F 0%, #F09819 100%)。这种暖色调的渐变非常醒目,能够在第一时间吸引用户的目光,激发用户的点击欲望。文字颜色设置为白色,与背景形成了鲜明的对比,确保了文字的清晰可读。font-size: 22px 和 font-weight: 600 的组合,使文字更加清晰、突出,增强了链接的辨识度。 border-radius: 15px 让链接按钮的边角更加圆润,给人一种柔和、舒适的感觉,避免了尖锐边角可能带来的生硬感。box-shadow: 0 8px 16px rgba(0, 0, 0, 0.15) 为链接按钮添加了一层淡淡的阴影效果,使其看起来更加立体、真实,仿佛具有一种“可触摸”的质感。 当鼠标悬停在链接上时,一系列精彩的动画效果随之呈现。transform: translateY(-7px) rotateX(10deg) 实现了链接按钮向上移动并旋转的动画效果,仿佛按钮在向用户发出邀请,增加了交互的趣味性。同时,box-shadow: 0 12px 24px rgba(0, 0, 0, 0.25) 增强了阴影效果,使按钮看起来更加突出和立体。背景渐变也随之反转,从原来的橙红色渐变变为相反的方向,这种变化不仅视觉上更加美观,还让用户能够明显感受到交互的反馈,进一步提升了用户体验。 四、使用指南 (一)保存与打开 如果你对这款福利源码发布页的HTML导航页源码感兴趣,想要将其保存并使用,以下是详细的操作步骤: 首先,打开一个专业的文本编辑器,如功能强大的 Notepad++、简洁高效的 Sublime Text 或者功能丰富的 Visual Studio Code 等。这些文本编辑器都具有良好的代码编辑功能,能够帮助你轻松地处理 HTML 代码。 然后,将上述源码复制到文本编辑器中。代码块右上角有复制按钮,当然如果你比较闲,可以使用鼠标选中代码,然后按下 Ctrl + C(在 Mac 系统上是 Command + C)进行复制,再在文本编辑器中按下 Ctrl + V(在 Mac 系统上是 Command + V)进行粘贴。 接下来,点击文本编辑器中的“文件”菜单,选择“保存”选项。在弹出的保存对话框中,将文件类型选择为“所有文件”,这样可以确保文件以 .html 扩展名保存。文件名可以根据自己的喜好进行命名,例如 navigation.html,但需要注意的是,文件扩展名必须为 .html,否则浏览器将无法正确识别和打开该文件。 最后,找到保存好的 .html 文件,双击该文件。此时,默认的浏览器将自动打开该文件。 (二)自定义修改 链接修改:如果你需要修改链接地址,或者想要添加新的网站链接,操作非常简单。只需找到 <ul> 标签内的 <li> 元素,每个 <li> 元素对应一个链接列表项。将 <a> 标签中的 href 属性值修改为你想要的网址即可。例如,如果你发现了一个新的网站,其网址为 https://www.newfulicode.cn,你可以在 <ul> 标签内添加一个新的 <li> 元素,其内容格式如下: <li><a href="https://www.newfulicode.cn" target="_blank"><i class="fa-solid fa-code"></i>新福利源码官网入口</a></li>这样,当用户访问导航页时,就可以通过点击新添加的链接访问到这个网站。 样式调整:若你对页面的样式不满意,想要根据自己的喜好进行调整,也可以在 <style> 标签内修改相应的 CSS 代码。例如,如果你觉得背景颜色不够鲜艳,可以修改 body 标签的 background 属性,选择你喜欢的颜色或渐变效果。如果你想调整链接按钮的颜色,可以修改 <a> 标签的 background 属性。通过对 CSS 代码的修改,你可以轻松地实现页面样式的个性化定制。 结语 希望各站长可以认识到这个我个人开发的导航页,其实还是不错滴
-
2025 必看!知识付费系统源码,三端合一开启躺赚模式 知识付费系统源码:小程序+PC+H5 三端联动,解锁知识变现新玩法 头图图片 前言 在知识经济蓬勃发展、日新月异的时代,知识付费已然成为一片充满无限潜力的新兴领域。对于渴望在这片领域中崭露头角的创业者、才华横溢的知识创作者,以及期望通过知识实现自我提升与财富增值的用户而言,一款功能强大、全面且灵活的知识付费系统,无疑是开启成功大门的关键钥匙。今天,就为大家揭开一款备受市场青睐、堪称年度爆款的知识付费系统——2024 年度热门全能知识付费平台源码的神秘面纱。它凭借小程序、PC 端和 H5 三端深度融合的卓越特性,彻底打破不同平台之间的隔阂,实现数据在各终端之间的无缝对接与自由流通,为用户打造出一种前所未有的便捷、流畅的使用体验。源码介绍 这款开源系统不仅拥有高效智能的资源采集与共享机制,能够让海量的知识资源在平台上迅速传播与广泛分享,更是创造性地融入了裂变增长模式。借助用户庞大的社交网络,该系统能够像病毒一样迅速扩散,实现平台用户数量与影响力的指数级增长,让每一位参与者都能在这场知识盛宴中收获满满。多元核心亮点,奠定行业领先地位 分站系统——独立运营,个性化发展的舞台:平台精心为每个分站配备独立的后台管理权限,这就如同为每一位分站运营者赋予了一座专属的“商业城堡”。在这里,他们可以依据当地独特的市场需求、深入了解的用户偏好,以及自身独特的运营理念与战略规划,灵活自如地制定全方位的运营策略。从分站页面的风格设计,到课程的精准定价,再到别出心裁的推广活动策划,一切都可以按照自己的意愿进行设置,真正实现个性化的发展路径。在激烈的市场竞争中,这种独特的运营模式能够帮助分站迅速脱颖而出,打造出属于自己的核心竞争力。 会员体系——深度连接用户,激发持续消费活力:一套完善且极具吸引力的会员制度,是增强用户粘性、促进用户持续消费的核心关键。该系统通过巧妙设置不同等级的会员权益,如优先获取平台上的优质稀缺资源、享受专属的折扣优惠、参与仅限会员的独家活动等,全方位满足用户多样化的需求。当用户在享受这些特权的过程中,他们对平台的认同感与忠诚度会不断攀升,从而形成长期稳定的消费习惯,为平台的长期稳定发展筑牢坚实的用户基础与经济根基。 卡密功能——便捷与安全并重,交易无忧的保障:便捷高效的商品激活与验证流程,是该系统备受用户赞誉的一大显著特色。当用户购买课程或其他各类知识产品后,只需简单输入卡密,即可快速完成激活并开始使用,无需经历繁琐复杂的注册与验证步骤。这种简洁明了的操作方式,不仅极大地提升了用户的使用体验,节省了宝贵的时间,更重要的是,它极大地提高了交易过程中的安全性。通过卡密验证机制,有效防止了盗版和恶意盗用等问题的发生,切实保障了知识创作者和平台的合法权益,让每一次知识交易都安全可靠。 二级分销——全民推广,互利共赢的财富密码:极具创新性的二级分销模式,为平台构建起了一个充满活力、良性循环的盈利生态系统。它充分激发每一位用户的积极性,鼓励他们成为平台的推广者。当推广者成功邀请新用户购买平台的产品或服务时,推广者便能获得相应比例的分销佣金。这种互利共赢的激励机制,不仅为平台带来了源源不断的新用户和丰厚的收益,同时也让用户在分享知识的过程中获得实实在在的经济回报。用户在享受知识带来的价值提升的同时,还能通过自身的社交影响力实现财富增值,进一步激发了用户的推广热情,形成一个可持续发展的良性循环。 匠心打磨,铸就卓越品质 这款知识付费系统能够达到如今的卓越水平,离不开专业团队的不懈努力与精心雕琢。目前,系统已成功升级至 3.5 版本,在这个版本中,之前版本存在的兼容性问题以及功能上的小瑕疵都得到了全面、彻底的修复与优化。专业团队不惜耗费整整三天的时间,对系统的每一行代码、每一个功能模块都进行了细致入微的打磨与测试。他们以追求极致的工匠精神,对系统的稳定性、流畅性以及用户体验进行了全方位的优化提升,确保系统在性能和功能上都达到行业顶尖水平,为用户提供无与伦比的使用感受。 小程序配置,轻松上手无压力 在小程序配置方面,该系统充分考虑到不同用户的实际情况,无论您的小程序是否已经完成认证,都能轻松实现与平台的完美对接。对于已经完成认证的小程序,操作过程简单便捷,只需直接上传 H5 代码,即可迅速完成与平台的无缝对接,快速搭建起属于自己的个性化知识付费小程序。而对于那些尚未完成认证的用户,也完全不必为此担忧。通过网页版 H5 及 PC 端,同样能够流畅无阻地访问平台的所有丰富功能,享受到与认证用户毫无差别的优质服务体验。无论是在功能的完整性,还是在使用的便捷性上,都不会因为小程序是否认证而受到任何影响。 此外,系统还充分考虑到用户在支付与登录过程中的便捷性与安全性需求。它支持微信支付、支付宝支付等多种当前主流的支付方式,满足不同用户的支付习惯。同时,配备了注册短信验证和微信登录等便捷高效的登录功能,让用户能够快速、轻松地进入平台。系统内置的完善提现流程,严格遵循金融安全标准,从提现申请的提交,到审核流程的规范,再到资金的安全到账,每一个环节都经过精心设计与严格把控,全方位保障用户的资金流转安全,让用户在平台上的每一次操作都安心无忧。 安装部署指南 服务器要求:服务器配置1h 2g以上均可使用,运行环境为php7.2、sql 5.6,记得开启防跨站点。 宝塔站点搭建:在宝塔新建个站点,php版本选择7.2,将“后端”文件夹里的文件上传到站点根目录,运行目录设置为/public,安装好SSL证书,伪静态设置为thinkphp。 数据库导入:导入sql数据库文件前,用notepad++软件打开数据库文件(切勿用记事本打开,否则会乱码),搜索127.0.0.1这个域名,批量替换为你的站点域名,然后导入数据库。 数据库配置修改:修改数据库配置文件,路径为/config/database.php,右键用n++打开(不要用记事本),在此处修改数据库相关设置。完成后,PC端基本搭建完成。入口为域名+yohutu,这便是后台登录地址,账号为admin,密码是123123,自行登录即可查看PC端效果,之后再进行H5的配置。值得一提的是,微信小程序、PC端、H5端三端数据互通,这三个端口的后台信息都能随意修改,后续会为大家演示,先看看后端情况,前端显示信息在后台也可随意修改,移动端还带有装修功能。 H5配置教程:解析一个二级域名,运行目录设置为frontend/h5。修改H5里面的配置文件,把wcceinfo.js文件里的域名修改成你PC的域名即可。由于小程序申请需要时间,暂时无法给大家演示小程序,但请放心,这是三端完整数据互通的系统。 下载 为了方便用户能够快速、顺利地下载使用,我们已将其上传至123网盘存储。点击下方即可轻松获取源码。 点击下载|最火的知识付费系统小程序源码+PC+H5三端.7z 下载地址:https://www.123684.com/s/rCKrjv-T8b8d 提取码:
-
全面解析 Element 框架:Vue.js 开发者的高效之选 Element框架介绍与教程 element图片 前言 在当下竞争激烈且技术迭代日新月异的Web开发领域,打造出兼具高效性能、精美外观以及卓越用户体验的应用程序,已然成为广大开发者们矢志不渝的核心追求。随着前端技术如汹涌浪潮般迅猛发展,开发者们在实际项目推进过程中,面临着诸多棘手挑战。像是如何在有限的时间内快速搭建出结构合理、布局美观的界面,怎样确保应用在各式各样的设备,从超宽屏的桌面显示器,到小巧便携的笔记本电脑,再到灵活多变的平板电脑和智能手机上,都能完美适配并稳定运行,以及怎样编写可维护性强、易于扩展的代码,以便在项目长期发展过程中,能够轻松应对不断变化的需求和可能出现的问题。Element框架,作为一款由福利源码(www.fulicode.cn)大力推荐的、基于Vue.js 2.0的强大桌面端组件库,犹如一把万能钥匙,为开发者们开启了一扇解决上述难题的大门,提供了一套全方位、多层次的优质解决方案。一、Element框架简介 Element框架是饿了么前端团队经过无数个日夜精心打磨后,慷慨开源奉献给广大开发者的瑰宝。它深度且巧妙地整合了Vue.js 2.0的诸多技术优势。Vue.js凭借其简洁明了、易于上手的API,能够让开发者快速熟悉并运用各种功能;高效智能的响应式数据绑定机制,无需开发者手动频繁更新DOM,数据一旦发生变化,页面就能自动同步更新,极大地提高了开发效率和应用的响应速度;还有灵活多变的组件化开发模式,允许开发者将复杂的页面拆分成一个个独立、可复用的组件,使得代码结构更加清晰,维护和扩展也更加方便。在Vue.js这些优势的坚实基础上,Element框架构建起了一套丰富多元且实用价值极高的UI组件体系。从最基础的布局组件,如el-container、el-row、el-col等,它们就像是搭建高楼大厦的基石,帮助开发者快速搭建出页面的整体框架,确定页面的布局结构;到各种交互性极强的组件,像按钮、表单、弹窗、导航栏等,一应俱全,几乎涵盖了桌面端Web应用开发过程中可能遇到的所有常见场景,无论是电商平台的商品展示与交易流程,还是企业内部管理系统的用户信息录入与数据查询,Element框架都能提供恰到好处的组件支持。 福利源码(www.fulicode.cn)深入分析后认为,Element框架的设计理念始终以简洁优雅为核心灵魂,将用户体验奉为圭臬。在视觉设计层面,它精心选用了简洁大方的色彩搭配,避免了繁杂刺眼的色调组合,让用户在浏览页面时,眼睛能够得到舒适的享受;同时运用清晰合理的排版布局,各个组件在页面中的位置、大小、间距等都经过精心计算和设计,确保在各种应用场景下,无论是简洁的信息展示页面,还是功能复杂的操作界面,都能呈现出一致且令人赏心悦目的视觉效果,完美契合现代用户对于界面美观和简洁的审美追求。不仅如此,Element框架还赋予了开发者高度的可定制性。开发者既可以通过修改CSS变量,对组件的颜色、字体大小、间距等基础样式进行细致入微的调整,实现个性化的视觉风格;也可以借助自定义主题功能,根据项目的独特需求,打造出独一无二、专属于项目的主题风格;甚至可以直接调整组件的props属性,实现对组件行为和功能的个性化定制,比如改变按钮的点击效果、表单的验证规则等,从而满足不同项目千差万别的多样化需求。 二、Element框架优势 (一)丰富的组件库 Element框架拥有一个规模庞大、功能完备到令人惊叹的组件库,这无疑是其在众多前端组件库中脱颖而出、最为显著的优势之一。以日常开发中频繁使用的按钮组件el-button为例,它就像是一个多功能的交互工具,提供了多种精心预定义的类型。primary类型的主要按钮,通常在电商平台中用于提交订单、确认支付等关键操作流程,其醒目的样式和突出的视觉效果,能够迅速吸引用户的注意力,引导用户顺利完成重要操作;success类型的成功按钮,在用户完成注册流程、文件成功上传等场景下发挥着重要作用,其清新的绿色色调和积极向上的视觉反馈,能够让用户及时了解到操作的成功状态,增强用户的操作信心和愉悦感;info类型的信息按钮,在需要传达一般性信息时,如产品详情页中的查看更多信息、帮助文档中的了解更多说明等场景,以其简洁低调的设计风格,在不干扰用户主要操作的前提下,恰到好处地提供必要的信息引导;warning类型的警告按钮,在涉及删除确认、余额不足提示等需要提醒用户注意潜在风险的场景中,其醒目的黄色警示色和独特的样式,能够有效引起用户的警觉,避免用户因疏忽而造成不必要的损失;danger类型的危险按钮,用于强调如永久删除重要数据、注销账号等不可逆的危险操作,其强烈醒目的红色设计和突出的样式,能够对用户形成强烈的警示,防止用户因误操作而造成严重后果。此外,el-button还支持开发者根据项目的具体需求,自定义按钮的样式和图标,比如在一个音乐播放应用中,可以为按钮添加音符图标,使其更贴合应用主题,为用户带来更加直观、有趣的交互体验。以下是福利源码(www.fulicode.cn)为大家精心准备的示例代码: <template> <div> <el-button type="primary" @click="handlePrimaryClick">主要按钮</el-button> <el-button type="success" @click="handleSuccessClick">成功按钮</el-button> <el-button type="info" @click="handleInfoClick">信息按钮</el-button> <el-button type="warning" @click="handleWarningClick">警告按钮</el-button> <el-button type="danger" @click="handleDangerClick">危险按钮</el-button> </div> </template> <script> export default { methods: { handlePrimaryClick() { console.log('主要按钮被点击,执行相关业务逻辑,比如跳转到订单确认页面'); }, handleSuccessClick() { console.log('成功按钮被点击,执行相关业务逻辑,比如显示成功提示弹窗'); }, handleInfoClick() { console.log('信息按钮被点击,执行相关业务逻辑,比如弹出信息详情弹窗'); }, handleWarningClick() { console.log('警告按钮被点击,执行相关业务逻辑,比如显示警告详情提示'); }, handleDangerClick() { console.log('危险按钮被点击,执行相关业务逻辑,比如再次确认删除操作'); } } } </script>表格组件el-table更是功能强大到超乎想象。除了具备基本的数据展示功能,能够将大量的数据以清晰、直观的表格形式呈现给用户,方便用户快速浏览和对比数据;它还内置了排序、筛选、分页等一系列高级功能,这些功能在企业级应用中尤为重要。在一个企业员工管理系统中,使用el-table展示员工列表时,通过排序功能,管理者可以根据员工姓名的字母顺序、年龄的大小、职位的高低等字段进行快速排序,方便查找和管理员工信息;筛选功能则允许管理者根据特定条件,如部门、入职时间等,精准筛选出符合要求的员工数据;分页功能能够避免一次性加载过多数据导致页面卡顿,将数据分页展示,提高用户体验。示例代码如下(福利源码,www.fulicode.cn): <template> <el-table :data="employeeList" style="width: 100%" :default-sort="{ prop: 'age', order: 'ascending' }"> <el-table-column prop="name" label="姓名" sortable></el-table-column> <el-table-column prop="age" label="年龄" sortable></el-table-column> <el-table-column prop="position" label="职位" sortable filterable></el-table-column> </el-table> </template> <script> export default { data() { return { employeeList: [ { name: '张三', age: 28, position: '前端开发工程师' }, { name: '李四', age: 32, position: '后端开发工程师' } ] }; } } </script>(二)响应式设计 在如今这个多设备浏览已然成为常态的时代,确保Web应用在不同屏幕尺寸下都能为用户提供始终如一的良好体验,已然成为前端开发工作中一项至关重要的任务。Element框架的所有组件在设计之初,就充分考虑到了这一关键需求,经过无数次的优化和测试,具备了卓越出色的响应式能力。无论是在大屏幕的桌面显示器上,能够充分展示页面丰富的内容和复杂的布局,为用户提供沉浸式的操作体验;还是在小尺寸的笔记本电脑屏幕上,依然能够保持界面的简洁和易用,不因为屏幕空间的限制而影响用户操作;甚至是在平板电脑等移动设备上,也能自动适应屏幕尺寸的变化,巧妙地调整布局和样式,为用户提供便捷高效的操作体验。以导航栏组件el-menu为例,在一个响应式的后台管理系统中,当屏幕宽度足够时,它会以水平模式展示,各个菜单项一目了然,用户可以通过鼠标轻松点击,快速切换不同的功能模块,提高工作效率;而当屏幕宽度较小时,它会自动切换为折叠式导航栏,通过简洁的图标和展开按钮,节省屏幕空间,同时又不影响用户对各个功能的访问和操作,用户只需轻轻点击图标,即可展开导航栏,查看和选择所需功能。以下是福利源码(www.fulicode.cn)提供的示例代码: <template> <el-menu :default-active="activeIndex" class="el-menu-demo" :collapse="isCollapse" :collapse-transition="false" @select="handleSelect"> <el-menu-item index="1">仪表盘</el-menu-item> <el-menu-item index="2">用户管理</el-menu-item> </el-menu> </template> <script> export default { data() { return { activeIndex: '1', isCollapse: false }; }, methods: { handleSelect(key, keyPath) { console.log(key, keyPath); }, handleResize() { if (window.innerWidth < 768) { this.isCollapse = true; } else { this.isCollapse = false; } } }, mounted() { window.addEventListener('resize', this.handleResize); this.handleResize(); }, beforeDestroy() { window.removeEventListener('resize', this.handleResize); } } </script>(三)易用性 Element框架的易用性堪称其一大核心竞争力,也是吸引众多开发者投身其中的重要因素之一。它拥有一套极为详细、直观且易于理解的官方文档,每一个组件都配备了清晰明了的使用说明,从基本的功能介绍,到常见的使用场景分析,再到具体的代码示例演示,都进行了全面而细致的阐述;同时,还提供了丰富多样的示例代码,涵盖了各种常见和特殊的应用场景,让开发者能够通过实际的代码演示,快速掌握组件的使用方法和技巧;此外,全面的API文档更是为开发者在深入使用组件时提供了有力的支持,无论是查看组件的属性、方法,还是了解事件的触发机制,都能在API文档中找到准确而详尽的信息。即使是那些没有太多前端开发经验的初学者,只要认真阅读Element的官方文档,也能够在短时间内快速上手并熟练使用Element组件。以表单组件el-form为例,使用它来创建一个用户登录表单是一件非常简单的事情。开发者只需按照文档中的示例,精心定义好表单数据模型form,明确各个表单字段的初始值和数据类型;制定完善的验证规则rules,确保用户输入的数据符合业务要求,比如用户名的长度限制、密码的强度要求等;并通过el-form-item组件将表单字段el-input进行合理包裹,即可轻松实现一个功能完备、交互友好的登录表单。福利源码(www.fulicode.cn)为大家准备的示例代码如下: <template> <el-form :model="form" :rules="rules" ref="form" label-width="80px"> <el-form-item label="用户名" prop="username"> <el-input v-model="form.username"></el-input> </el-form-item> <el-form-item label="密码" prop="password"> <el-input type="password" v-model="form.password"></el-input> </el-form-item> <el-form-item> <el-button type="primary" @click="submitForm('form')">登录</el-button> <el-button @click="resetForm('form')">重置</el-button> </el-form-item> </el-form> </template> <script> export default { data() { return { form: { username: '', password: '' }, rules: { username: [ { required: true, message: '请输入用户名', trigger: 'blur' }, { min: 3, max: 20, message: '用户名长度需在3到20位之间', trigger: 'blur' } ], password: [ { required: true, message: '请输入密码', trigger: 'blur' }, { min: 6, message: '密码长度至少为6位', trigger: 'blur' } ] } }; }, methods: { submitForm(formName) { this.$refs[formName].validate((valid) => { if (valid) { console.log('登录成功,执行登录逻辑,如发送登录请求到服务器,验证用户身份'); } else { console.log('校验失败,提示用户输入正确信息,如用户名或密码错误'); return false; } }); }, resetForm(formName) { this.$refs[formName].resetFields(); } } } </script>(四)良好的社区支持 Element框架拥有一个庞大且充满活力的开发者社区,这无疑为其持续发展和不断壮大提供了源源不断的强大动力,同时也为广大开发者在使用Element框架的过程中提供了坚实可靠的支持和保障。在这个社区中,来自五湖四海、各行各业的开发者们汇聚一堂,他们可以毫无保留地相互交流在使用Element过程中遇到的各种问题,分享自己在实践中积累的宝贵经验和独特技巧。当开发者在项目开发过程中遭遇难题时,能够通过社区论坛、技术问答平台等多种渠道,迅速搜索到相关的解决方案,或者向其他经验丰富的开发者提问求助,往往能够在短时间内获得有效的帮助和指导。同时,社区中还涌现出了许多基于Element开发的优秀开源项目和插件,这些开源项目和插件进一步拓展了Element的应用场景和功能边界。例如,一些开发者基于Element开发了可视化的表单生成器插件,使得开发者无需编写大量繁琐的代码,就能通过简单的拖拽操作,快速生成复杂的表单,大大提高了表单开发的效率和灵活性;还有一些开源项目基于Element构建了完整的后台管理系统模板,包含了常见的功能模块和页面布局,开发者可以直接下载使用,并在此基础上进行二次开发,极大地缩短了项目的开发周期,提高了开发效率。福利源码(www.fulicode.cn)建议大家积极参与社区交流,与其他开发者共同学习、共同进步,获取更多开发灵感和优质资源。 三、Element框架教程 (一)安装Element 1. 使用npm安装 如果你使用的是npm包管理器,在项目目录下打开命令行终端,执行以下命令(福利源码,www.fulicode.cn): npm i element-ui -S这行命令会通过npm从npm仓库中精准地下载Element UI库及其所有依赖项,并将它们妥善安装到项目的node_modules目录中。同时,element-ui会被自动添加到项目的package.json文件的dependencies字段中,这一操作不仅方便了后续项目依赖的管理,还能确保在项目迁移或团队协作时,所有依赖的版本能够得到准确的记录和控制,为项目的稳定运行提供了有力保障。需要注意的是,在安装过程中,如果遇到网络问题导致下载失败,可以尝试更换网络环境或者使用npm的镜像源,如淘宝镜像源,以提高下载速度和稳定性。 2. 使用yarn安装 如果你选择使用yarn作为包管理器,执行以下命令即可完成安装: yarn add element-uiyarn会自动从yarn仓库中获取Element UI库及其依赖,并将它们高效地安装到项目中。与npm类似,element-ui也会被记录到package.json文件中。值得一提的是,yarn在安装过程中会采用更为先进的依赖解析算法和智能的缓存管理机制,通常能够显著加快安装速度,尤其是在处理复杂的依赖关系时,yarn的优势更加明显,能够为开发者节省宝贵的时间。此外,yarn还支持并行安装,即同时下载多个依赖包,大大缩短了整体安装时间。在大型项目中,依赖包数量众多,yarn的这一特性优势尤为突出。比如在一个包含数十个依赖的企业级项目中,使用yarn安装Element UI及其他相关依赖,相较于npm,可能会节省数分钟甚至更多的安装时间,这对于频繁进行项目搭建和环境配置的开发者来说,能够显著提高工作效率。 (二)引入Element 1. 全局引入 在项目的入口文件main.js中添加以下代码(福利源码,www.fulicode.cn): import Vue from 'vue'; import ElementUI from 'element-ui'; import 'element-ui/lib/theme-chalk/index.css'; import App from './App.vue'; Vue.use(ElementUI); new Vue({ el: '#app', render: h => h(App) });通过Vue.use(ElementUI),我们将Element UI全局注册到Vue实例中。这意味着在整个项目的任何组件中,都可以直接使用Element的组件,无需再次单独引入,极大地简化了开发流程。同时,引入element-ui/lib/theme-chalk/index.css来加载Element的默认样式,确保组件在页面中呈现出统一、美观的视觉效果。需要注意的是,若项目中使用了自定义主题,应根据主题的实际路径引入相应的样式文件,而非默认的theme-chalk样式。此外,在全局引入时,若项目中存在多个Vue实例,要确保Element UI注册在正确的Vue实例上,以免出现组件无法使用或样式错乱的问题。 2. 局部引入 如果你只想在某个特定的组件中使用Element组件,可以在该组件中进行局部引入。例如,在一个Login.vue组件中,只需要使用按钮和弹窗组件: import { Button, MessageBox } from 'element-ui'; import 'element-ui/lib/theme-chalk/button.css'; import 'element-ui/lib/theme-chalk/message-box.css'; export default { components: { ElButton: Button }, methods: { showMessageBox() { MessageBox.alert('这是一个消息提示框'); } } }在模板中使用: <template> <div> <el-button @click="showMessageBox">点击显示提示框</el-button> </div> </template>局部引入的方式适用于某些组件仅在特定页面或组件中使用的场景。这种方式能够有效减少不必要的资源加载,优化项目的性能。例如,在一个大型电商项目中,购物车页面可能只需要使用el-button和el-dialog组件来实现商品的删除确认和结算操作,通过局部引入这两个组件,而不是全局引入整个Element UI库,能够显著减少页面的初始加载时间,提升用户体验。不过,在局部引入时,要注意组件样式文件的引入路径是否正确,否则可能会导致组件样式丢失。同时,若多个组件都局部引入了相同的Element组件,应确保版本一致,避免出现兼容性问题。 (三)使用Element组件 Element组件的使用方式非常直观,以按钮组件为例,在模板中可以这样使用: <template> <div> <el-button type="primary">主要按钮</el-button> <el-button type="success">成功按钮</el-button> <el-button type="info">信息按钮</el-button> <el-button type="warning">警告按钮</el-button> <el-button type="danger">危险按钮</el-button> </div> </template>除了基本的按钮类型,还可以设置按钮的大小、是否禁用等属性: <template> <div> <el-button type="primary" size="medium">中等大小主要按钮</el-button> <el-button type="success" size="small" :disabled="true">禁用的小成功按钮</el-button> </div> </template>在实际项目中,按钮的使用场景非常丰富。比如在一个在线教育平台中,“开始学习”按钮可以设置为primary类型,吸引用户点击进入课程学习;当用户完成课程学习并通过测试后,“完成课程”按钮可以设置为success类型,给予用户积极的反馈。 再比如,使用表格组件展示数据: <template> <el-table :data="userList" style="width: 100%"> <el-table-column prop="name" label="姓名"></el-table-column> <el-table-column prop="age" label="年龄"></el-table-column> <el-table-column prop="email" label="邮箱"></el-table-column> </el-table> </template> <script> export default { data() { return { userList: [ { name: '张三', age: 25, email: 'zhangsan@fulicode.cn' }, { name: '李四', age: 30, email: 'lisi@fulicode.cn' } ] }; } } </script>对于表格组件,当数据量较大时,可以结合分页功能,通过el-pagination组件实现数据的分页展示。例如: <template> <div> <el-table :data="userList.slice((currentPage - 1) * pageSize, currentPage * pageSize)" style="width: 100%"> <el-table-column prop="name" label="姓名"></el-table-column> <el-table-column prop="age" label="年龄"></el-table-column> <el-table-column prop="email" label="邮箱"></el-table-column> </el-table> <el-pagination :current-page="currentPage" :page-sizes="[10, 20, 30, 40]" :page-size="pageSize" layout="total, sizes, prev, pager, next, jumper" :total="userList.length" @current-change="handleCurrentChange" @size-change="handleSizeChange"> </el-pagination> </div> </template> <script> export default { data() { return { userList: [ { name: '张三', age: 25, email: 'zhangsan@fulicode.cn' }, // 更多用户数据 ], currentPage: 1, pageSize: 10 }; }, methods: { handleCurrentChange(page) { this.currentPage = page; }, handleSizeChange(size) { this.pageSize = size; this.currentPage = 1; } } } </script>在使用Element组件时,还可以利用其提供的事件和方法,实现更复杂的交互逻辑。例如,在表单组件中,除了基本的验证功能,还可以通过el-form的validateField方法,对单个字段进行动态验证。在一个用户注册表单中,当用户输入用户名后,失去焦点时,可以调用validateField方法,实时验证用户名是否已被注册: <template> <el-form :model="registerForm" :rules="registerRules" ref="registerForm" label-width="100px"> <el-form-item label="用户名" prop="username"> <el-input v-model="registerForm.username" @blur="validateUsername"> </el-input> </el-form-item> <!-- 其他表单字段 --> </el-form> </template> <script> export default { data() { return { registerForm: { username: '' }, registerRules: { username: [ { required: true, message: '请输入用户名', trigger: 'blur' } ] } }; }, methods: { validateUsername() { this.$refs.registerForm.validateField('username', (error) => { if (error) { // 处理验证失败逻辑 } else { // 调用后端接口验证用户名是否已存在 // 根据验证结果进行相应处理 } }); } } } </script>结语 Element框架还有许多高级功能和用法,如自定义主题、组件的高级配置、动态组件加载等。福利源码(www.fulicode.cn)提醒大家,在实际使用中遇到问题,或者想要深入了解更多高级特性,可以参考Element的官方文档,其中包含了丰富的教程和示例,能够帮助你更好地掌握Element框架。通过不断学习和实践,相信你能够充分发挥Element框架的优势,打造出优秀的Web应用程序。
-
[亲测]鲸发卡 v11.71 企业级发卡系统源码下载 鲸发卡v11.71企业级发卡系统源码:虚拟商品交易的高效解决方案 在互联网经济蓬勃发展的当下,虚拟商品交易市场呈现出迅猛的扩张态势。游戏点卡、软件激活码、视频会员等数字产品的交易需求与日俱增,这片商业领域充满了机遇,同时也面临着激烈的竞争。在这样的环境中,一款功能强大且运行稳定的发卡系统,成为众多从业者在竞争中脱颖而出的关键因素。鲸发卡v11.71企业级发卡系统源码,以其卓越的性能、丰富的功能以及出色的用户体验,走进大众的视野,为虚拟商品交易从业者提供了全新的发展契机,有力地推动行业迈向新的发展阶段。 一、卓越体验,轻松上手 鲸发卡系统在发卡行业中一直占据着领先地位,堪称行业的标杆。其操作界面设计秉持着简洁、直观、易用的核心理念,充分考虑到不同用户群体的使用习惯和技能水平。即便是从未接触过此类系统的新手,在初次使用鲸发卡系统时,也能轻松理解操作步骤。系统的操作步骤清晰明了,引导提示精准无误,用户能够在短时间内熟悉各项功能,顺利开启虚拟商品交易业务。这大大降低了行业的准入门槛,为更多创业者提供了平等参与市场竞争的机会。 v11.71版本在用户体验方面投入了大量的精力,对系统主页UI进行了全面升级。此次升级彻底改变了传统模板单调、沉闷、缺乏特色的状况,以全新的视觉风格震撼登场。设计团队精心优化每一个细节,从色彩搭配到元素布局,都经过了反复的斟酌和打磨,力求为用户打造出既美观又实用的操作界面。 网站前台图片 此次更新,鲸发卡v11.71版本新增了三套最新模板,在模板数量和类型上,充分满足了不同用户在不同设备上的个性化需求。PC端拥有4套精美的首页模板,每套模板的设计风格和功能布局都独具特色。无论是追求简约时尚现代风格的用户,还是偏好大气稳重商务风格的用户,都能在这里找到最适合自身业务的模板。手机端同样配备4套首页模板,其中3套与PC端相同,保证了用户在不同设备上使用时体验的一致性。无论你是在电脑前专注办公,还是通过手机随时随地处理业务,都能获得舒适的使用体验。 二、功能升级,精准优化 鲸发卡v11.71版本在功能优化与修复方面,精准地针对用户痛点,每一项改进都基于深入的市场调研和用户反馈分析,极具针对性和实用性。 短链接生成与重置功能经过深度优化,效果得到了显著提升。过去,许多用户在推广商品时,常常因为短链接生成速度慢、稳定性差而苦恼,这不仅严重影响了推广效率,还可能导致潜在客户的流失。鲸发卡v11.71版本通过优化算法和服务器配置,大幅提升了短链接生成速度,近乎实现了瞬间生成。同时,显著增强了链接的稳定性,即使在高并发的情况下,也能保证链接的正常访问,不会出现卡顿或失效的情况。这一优化让用户在推广商品时更加高效,能够精准地将商品信息传递给目标人群,吸引更多潜在客户,为业务增长注入强大的动力。 客户端新版本UI不仅外观更加美观大气,操作流程也得到了全方位的优化。从界面布局来看,各个功能模块的划分更加清晰合理,用户能够在最短的时间内找到自己需要的功能入口。交互设计采用了更加人性化的操作方式,如滑动、点击的反馈更加灵敏,动画效果更加流畅,让用户在使用过程中感受到前所未有的愉悦体验。比如在商品搜索功能中,用户只需输入关键词,系统就能迅速给出精准的搜索结果,并以简洁明了的方式展示出来,大大节省了用户的时间和精力。 邀请码无限重复生成功能也得到了优化,成功解决了之前版本中后台无法关闭该功能的问题。在实际运营中,许多平台运营者需要根据不同的营销活动和用户管理策略,灵活控制邀请码的生成与使用。旧版本由于无法关闭邀请码无限重复生成功能,导致部分不良用户利用这一漏洞进行恶意注册,给平台带来了安全隐患和运营成本的增加。鲸发卡v11.71版本改进了代码逻辑,为运营者提供了更加灵活的控制权限,运营者可以根据实际业务需求,随时开启或关闭邀请码无限重复生成功能,实现对用户群体的精细化管理,有效提升了平台的安全性和运营效率。 三、安装配置,步步为营 环境准备,打好基础 在安装鲸发卡v11.71系统源码之前,确保服务器环境满足php7.0、mysql5.6的要求至关重要。php7.0具有执行效率高、兼容性好的特点,能够为鲸发卡系统的稳定运行提供强大的技术支持。mysql5.6作为一款成熟的数据库管理系统,具备高效的数据存储和检索能力,可确保系统在处理大量交易数据时的准确性和及时性。 同时,要正确设置伪静态thinkphp,并将运行目录设置为/public。伪静态设置能够提高网站的访问速度和搜索引擎优化效果,使用户在访问网站时能够更快地加载页面。将运行目录设置为/public,可确保系统文件的安全、规范,便于后续的维护和管理。每个步骤都紧密相连,只有严格按照要求配置,才能为后续的安装和使用创造良好的条件,确保系统能够顺利运行。 安装与初始设置,安全第一 安装页面的默认密码为123456,这是为了方便用户在安装过程中快速进入系统进行初步设置。然而,在安装完成后,务必及时在后台修改密码,这是保障系统安全的重要举措。简单易猜的密码存在着极大的安全风险,可能被不法分子利用,从而导致用户数据泄露、系统被攻击等严重后果。因此,建议用户设置包含字母、数字、特殊字符的复杂高强度密码,并定期进行更换,为自己的业务筑牢安全防线。 运营准备配置,缺一不可 域名设置:在后台设置中准确填写域名项,包括主站域名和店铺推广域名。主站域名是用户访问平台的主要入口,简洁易记的主站域名便于用户记忆,有助于提高品牌知名度。店铺推广域名用于推广,通过设置不同的推广域名,运营者可以精准跟踪和分析不同渠道的推广效果,进而优化推广策略,提高推广效率。只有域名设置正确,用户才能顺利访问和推广平台,为业务发展奠定坚实的基础。 邮箱配置:合理配置邮箱,搭建起系统与用户之间沟通的桥梁。在虚拟商品交易中,邮箱起着至关重要的作用。订单通知可以让用户及时了解自己的购买情况;密码找回功能帮助用户在忘记密码时能够快速恢复访问权限;促销活动通知、系统更新公告等重要信息也可以通过邮箱及时、准确地传达给用户,确保沟通的顺畅无阻。稳定可靠的邮箱配置,能够增强用户对平台的信任,提升用户粘性。 支付设置:支付功能是发卡系统的核心,直接影响着交易的成败。鲸发卡v11.71版本支持多种支付方式,满足用户多样化的支付需求。在进行支付设置时,需要参考鲸官方易支付配置文档,配置过程涉及支付接口对接、密钥设置等多个环节,需要耐心和细心。但只要仔细研读文档,按照步骤操作,就能成功接入微信支付、支付宝支付、银行卡支付等多种支付方式。这样,用户在购买虚拟商品时,就可以根据自身的喜好和习惯选择最便捷的支付方式,大大提高了交易的成功率和用户满意度。 计划任务设置:依据鲸官方文档中的计划任务说明,精准设置4个计划任务。这些计划任务保障着系统的稳定运行和各项功能的正常执行。例如,订单处理计划任务能够及时处理用户的订单,确保商品能够及时发放到用户手中;数据统计计划任务可以定期统计和分析系统中的交易数据,为运营者提供决策依据,帮助运营者了解用户行为、市场趋势等信息,从而优化业务策略,提升运营效率。每个计划任务都不可或缺,它们协同工作,共同保障系统的稳定运行和业务的顺利发展。 后台首页图片 立即下载,开启商业新征程 如果您渴望在虚拟商品交易领域一展身手,鲸发卡v11.71企业级发卡系统源码将是您的不二之选。现在就可以通过以下方式获取: 123云盘下载 鲸发卡11.71免授权源码.zip 下载地址:https://www.123684.com/s/rCKrjv-dXb8d? 提取码:FLYM 鲸发卡v11.71企业级发卡系统源码,凭借其强大的功能、便捷的操作和贴心的配置选项,为虚拟商品交易提供了一套完善的解决方案。无论您是初入行业的创业者,怀揣着梦想与激情,渴望在虚拟商品交易领域崭露头角;还是已经在该领域深耕多年的资深从业者,希望进一步提升业务效率,拓展市场份额,鲸发卡v11.71都将是您不可或缺的得力助手。它将为您的业务发展注入强大动力,引领您在竞争激烈的虚拟商品交易市场中乘风破浪,驶向成功的彼岸。选择鲸发卡v11.71,就是选择开启一段充满无限可能的商业之旅。
-
HTML 跳转页面源码分享 | 打造美观高效的跳转体验 分享一个简单而美观的HTML跳转页面源码 在网页开发中,我们经常会遇到需要实现页面跳转的场景,比如引导用户从一个临时页面跳转到正式的网站页面。今天就来给大家分享一个简单且美观的HTML跳转页面源码,它不仅能实现基本的跳转功能,还通过精心设计的样式和动画效果,给用户带来良好的视觉体验。 效果预览 效果预览图片 一、功能介绍 这个HTML页面主要实现了在指定时间后自动跳转到目标网址的功能。同时,页面整体经过美化,具有渐变背景、淡入动画、加载提示等元素,使页面看起来更加生动和专业。 二、关键代码解析 (一)HTML结构 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>即将跳转</title> <style> /* 通用样式重置,去除浏览器默认样式差异 */ * { margin: 0; padding: 0; box-sizing: border-box; } /* 整体页面背景样式 */ body { font-family: 'Poppins', sans-serif; background: linear-gradient(135deg, #fdfcfb, #e2d1c3); display: flex; justify-content: center; align-items: center; min-height: 100vh; overflow: hidden; animation: fadeInBg 1.2s ease forwards; } /* 背景渐变动画 */ @keyframes fadeInBg { from { opacity: 0; } to { opacity: 1; } } /* 包裹提示内容的容器样式 */ .container { max-width: 450px; background-color: rgba(255, 255, 255, 0.9); border-radius: 20px; box-shadow: 0 10px 20px rgba(0, 0, 0, 0.15); padding: 45px; text-align: center; animation: fadeInContainer 1.2s ease 0.3s forwards; opacity: 0; } /* 容器淡入动画 */ @keyframes fadeInContainer { from { opacity: 0; transform: translateY(30px); } to { opacity: 1; transform: translateY(0); } } h1 { color: #333; font-size: 32px; margin-bottom: 25px; font-weight: 700; text-shadow: 1px 1px 3px rgba(0, 0, 0, 0.1); } p { color: #666; font-size: 20px; line-height: 1.6; margin-bottom: 35px; } /* 加载动画样式 */ .loader { border: 6px solid #f5f5f5; border-top: 6px solid #3498db; border-radius: 50%; width: 50px; height: 50px; animation: spin 1.5s linear infinite; margin: 0 auto 25px; } /* 加载动画旋转效果 */ @keyframes spin { 0% { transform: rotate(0deg); } 100% { transform: rotate(360deg); } } </style> <script> // 目标网址,此处定义为https://www.fulicode.cn,可根据实际需求修改此处的网址 const targetUrl = 'https://www.fulicode.cn'; // 定义跳转秒数变量,这里设置为1秒,可根据需求修改此值 const jumpSeconds = 1; window.onload = function () { // 页面加载完成后启动定时器,按照设定的秒数跳转到目标网址 setTimeout(() => { window.location.href = targetUrl; }, jumpSeconds * 1000); }; </script> </head> <body> <div class="container"> <div class="loader"></div> <h1>页面正在加载,即将跳转...</h1> <p>请稍作等待,精彩内容即将呈现。</p> </div> </body> </html>(二)CSS样式 通用样式重置:使用*选择器,将所有元素的内外边距设置为0,并将盒模型设置为border - box,确保在不同浏览器下样式的一致性。 页面背景: 为body元素设置了线性渐变背景background: linear-gradient(135deg, #fdfcfb, #e2d1c3),从浅米色到淡黄色的渐变,营造出柔和的视觉效果。 通过display: flex、justify-content: center和align-items: center使页面内容在水平和垂直方向上都居中显示。 min - height: 100vh确保页面高度至少为视口高度,overflow: hidden隐藏溢出内容,避免出现滚动条。同时,定义了fadeInBg动画,使背景在1.2秒内从透明淡入到不透明。 内容容器: .container类定义了包裹提示内容的容器样式。设置了最大宽度max - width: 450px,背景色为带有透明度的白色background - color: rgba(255, 255, 255, 0.9),增加了通透感。 边框使用border - radius: 20px设置为圆角,box - shadow: 0 10px 20px rgba(0, 0, 0, 0.15)添加了阴影效果,使容器更具立体感。 容器具有fadeInContainer动画,在页面加载0.3秒后开始,1.2秒内从上方移动并淡入显示。 文字样式: h1标题设置了字体大小32px、颜色#333、加粗font - weight: 700以及文字阴影text - shadow: 1px 1px 3px rgba(0, 0, 0, 0.1),使其更加醒目。 p段落文字设置了字体大小20px、颜色#666和行间距line - height: 1.6,保证了良好的可读性。 加载动画: .loader类创建了一个加载动画,通过设置圆形边框border: 6px solid #f5f5f5; border - top: 6px solid #3498db,顶部边框为蓝色,其余为浅灰色。 使用animation: spin 1.5s linear infinite定义了旋转动画,使加载图标以1.5秒的周期无限旋转。 (三)JavaScript逻辑 变量定义: 定义了targetUrl变量存储目标跳转网址,初始值为https://www.fulicode.cn,可以根据实际需求轻松修改。 定义了jumpSeconds变量设置跳转前等待的秒数,默认为1秒,也可按需调整。 页面跳转逻辑: 使用window.onload事件监听页面加载完成。 当页面加载完成后,通过setTimeout函数启动定时器,在jumpSeconds秒后(乘以1000转换为毫秒),使用window.location.href将页面跳转到targetUrl指定的网址。 三、使用方法 将上述代码复制到一个文本编辑器中。 根据自己的需求修改targetUrl变量为你想要跳转的目标网址。 可以调整jumpSeconds变量来改变跳转前的等待时间。 保存文件,将文件扩展名修改为.html。 用浏览器打开该HTML文件,即可看到效果。 通过这个简单的HTML跳转页面源码,你可以快速搭建一个美观且实用的跳转页面。无论是用于网站的临时过渡页面,还是引导用户进入特定页面,都能为用户带来不错的体验。希望这个源码分享对你有所帮助!如果你在使用过程中有任何问题,或者有更好的优化建议,欢迎交流分享。
-
抖音数据采集分析工具 Python 源码免费下载 - 深度洞察抖音数据的利器 抖音数据采集分析工具Python源码免费大放送,开启数据洞察新征程 在当今数字化浪潮席卷全球的时代,数据已然成为各行各业发展的核心驱动力。尤其是在短视频领域,抖音作为行业的佼佼者,蕴含着海量的数据宝藏。为了帮助广大用户能够更加便捷、高效地挖掘这些数据背后的价值,我们怀着激动的心情向大家宣布——抖音作品数据采集分析工具的Python源码正式对外开放,而且完全免费! 这款精心打造的工具,堪称内容创作者与市场分析师的“得力神兵”。对于内容创作者来说,通过对抖音作品数据的深入分析,能够精准洞察观众的喜好与需求,从而创作出更贴合市场、更具吸引力的优质内容,提升自身在抖音平台的影响力与竞争力。对于市场分析师而言,该工具采集的丰富数据,能够为市场趋势研究、竞品分析等提供坚实的数据支撑,帮助企业制定更加科学、有效的市场策略。 截图 使用截图图片 一、技术细节与使用要点 (一)代码编写与调试 本工具的代码是基于cursor编写而成,这一技术架构为工具的数据采集与分析功能奠定了坚实的基础。然而,就像任何一款处于不断优化过程中的软件产品一样,目前代码存在部分报错情况,并且个别模块尚未调试完善。但这并非是阻碍,而是为广大技术爱好者提供了一个施展才华的舞台。对于那些拥有扎实技术功底、热衷于探索与创新的用户而言,这无疑是一次难得的机会。你可以深入到代码的世界中,通过自己的智慧和努力,对这些问题进行调试与优化,不仅能够让工具更加符合自己的使用需求,还能在这个过程中提升自己的编程技能。 (二)配置要求 在使用该工具之前,有一个关键的准备步骤,那就是用户需要自行配置谷歌浏览器驱动。谷歌浏览器驱动在工具的数据采集过程中起着至关重要的桥梁作用,它能够确保工具与浏览器之间的通信顺畅,从而实现高效的数据采集。虽然这一配置过程可能需要花费一些时间和精力,但当你成功完成配置,看到工具顺利运行并为你采集到所需的数据时,一切的付出都将得到丰厚的回报。 二、使用便捷性:代码获取方式 为了最大程度地方便大家获取,我们将代码精心保存为文件,并提供了云盘下载渠道。这种方式不仅确保了代码的完整性,还让用户能够轻松快捷地将代码下载到本地,随时开始自己的数据采集与分析之旅。 当然你也可以复制粘贴↓ #您下载的资源来着www.fulicode.cn import tkinter as tk from tkinter import ttk, messagebox from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time import threading import pandas as pd import json from datetime import datetime import os from urllib.parse import quote from bs4 import BeautifulSoup import jieba from collections import Counter import traceback class DouyinAnalyzer: def __init__(self, root): self.root = root self.root.title("抖音作品分析工具") self.root.geometry("800x600") # 创建变量 self.url = tk.StringVar(value="https://www.douyin.com") self.scroll_count = tk.StringVar(value="100") self.delay = tk.StringVar(value="2") self.is_running = False self.collected_data = [] # 创建界面 self.create_widgets() def create_widgets(self): # 创建notebook用于标签页 self.notebook = ttk.Notebook(self.root) self.notebook.pack(fill='both', expand=True, padx=5, pady=5) # 创建各个标签页 self.create_collection_tab() self.create_data_tab() self.create_user_data_tab() self.create_analysis_tab() self.create_help_tab() # 添加帮助标签页 def create_collection_tab(self): """创建数据采集标签页""" collection_frame = ttk.Frame(self.notebook) self.notebook.add(collection_frame, text='数据采集') # URL输入框 url_frame = ttk.LabelFrame(collection_frame, text='数据来源') url_frame.pack(fill='x', padx=5, pady=5) ttk.Label(url_frame, text="抖音链接:").pack(side='left', padx=5) ttk.Entry(url_frame, textvariable=self.url, width=50).pack(side='left', padx=5) # 添加搜索框架 search_frame = ttk.LabelFrame(collection_frame, text='关键词搜索') search_frame.pack(fill='x', padx=5, pady=5) # 搜索关键词输入 keyword_frame = ttk.Frame(search_frame) keyword_frame.pack(fill='x', padx=5, pady=5) ttk.Label(keyword_frame, text="搜索关键词:").pack(side='left', padx=5) self.search_keyword = tk.StringVar() ttk.Entry(keyword_frame, textvariable=self.search_keyword, width=50).pack(side='left', padx=5) # 搜索类型选择(单选框) type_frame = ttk.Frame(search_frame) type_frame.pack(fill='x', padx=5, pady=5) ttk.Label(type_frame, text="搜索类型:").pack(side='left', padx=5) self.search_type = tk.StringVar(value='video') search_types = [ ('视频', 'video'), ('用户', 'user'), ('音乐', 'music'), ('话题', 'hashtag') ] # 创建单选框 for text, value in search_types: ttk.Radiobutton( type_frame, text=text, value=value, variable=self.search_type ).pack(side='left', padx=10) # 参数设置框 param_frame = ttk.LabelFrame(collection_frame, text='采集参数') param_frame.pack(fill='x', padx=5, pady=5) ttk.Label(param_frame, text="滚动次数:").pack(side='left', padx=5) ttk.Entry(param_frame, textvariable=self.scroll_count, width=10).pack(side='left', padx=5) ttk.Label(param_frame, text="延迟(秒):").pack(side='left', padx=5) ttk.Entry(param_frame, textvariable=self.delay, width=10).pack(side='left', padx=5) # 按钮框 button_frame = ttk.Frame(collection_frame) button_frame.pack(pady=10) ttk.Button(button_frame, text="搜索采集", command=self.start_search_collection).pack(side='left', padx=5) ttk.Button(button_frame, text="停止采集", command=self.stop_collection).pack(side='left', padx=5) # 状态栏 status_frame = ttk.Frame(collection_frame) status_frame.pack(fill='x', pady=5) self.status_label = ttk.Label(status_frame, text="就绪") self.status_label.pack(side='left', padx=5) self.progress = ttk.Progressbar(status_frame, length=300, mode='determinate') self.progress.pack(side='left', padx=5) def create_data_tab(self): """创建数据查看标签页""" data_frame = ttk.Frame(self.notebook) self.notebook.add(data_frame, text='数据查看') # 创建工具栏 toolbar = ttk.Frame(data_frame) toolbar.pack(fill='x', padx=5, pady=5) # 添加导出按钮 ttk.Button(toolbar, text="导出Excel", command=self.export_excel).pack(side='left', padx=5) ttk.Button(toolbar, text="导出JSON", command=self.export_json).pack(side='left', padx=5) # 添加统计标签 self.stats_label = ttk.Label(toolbar, text="共采集到 0 条数据") self.stats_label.pack(side='right', padx=5) # 创建表格 columns = ('序号', '标题', '作者', '发布时间', '点赞数', '视频链接') self.data_tree = ttk.Treeview(data_frame, columns=columns, show='headings') # 设置列标题和宽度 for col in columns: self.data_tree.heading(col, text=col, command=lambda c=col: self.treeview_sort_column(self.data_tree, c, False)) # 设置列宽 self.data_tree.column('序号', width=50) self.data_tree.column('标题', width=200) self.data_tree.column('作者', width=100) self.data_tree.column('发布时间', width=100) self.data_tree.column('点赞数', width=70) self.data_tree.column('视频链接', width=200) # 添加滚动条 scrollbar = ttk.Scrollbar(data_frame, orient='vertical', command=self.data_tree.yview) self.data_tree.configure(yscrollcommand=scrollbar.set) # 使用grid布局管理器 self.data_tree.pack(side='left', fill='both', expand=True) scrollbar.pack(side='right', fill='y') # 绑定双击事件 self.data_tree.bind('<Double-1>', self.on_tree_double_click) def create_user_data_tab(self): """创建用户数据查看标签页""" user_frame = ttk.Frame(self.notebook) self.notebook.add(user_frame, text='用户数据') # 创建工具栏 toolbar = ttk.Frame(user_frame) toolbar.pack(fill='x', padx=5, pady=5) # 添加导出按钮 ttk.Button(toolbar, text="导出Excel", command=self.export_user_excel).pack(side='left', padx=5) ttk.Button(toolbar, text="导出JSON", command=self.export_user_json).pack(side='left', padx=5) # 添加统计标签 self.user_stats_label = ttk.Label(toolbar, text="共采集到 0 位用户") self.user_stats_label.pack(side='right', padx=5) # 创建表格 columns = ('序号', '用户名', '抖音号', '获赞数', '粉丝数', '简介', '主页链接', '头像链接') self.user_tree = ttk.Treeview(user_frame, columns=columns, show='headings') # 设置列标题和排序功能 for col in columns: self.user_tree.heading(col, text=col, command=lambda c=col: self.treeview_sort_column(self.user_tree, c, False)) # 设置列宽 self.user_tree.column('序号', width=50) self.user_tree.column('用户名', width=150) self.user_tree.column('抖音号', width=100) self.user_tree.column('获赞数', width=70) self.user_tree.column('粉丝数', width=70) self.user_tree.column('简介', width=200) self.user_tree.column('主页链接', width=150) self.user_tree.column('头像链接', width=150) # 添加滚动条 scrollbar = ttk.Scrollbar(user_frame, orient='vertical', command=self.user_tree.yview) self.user_tree.configure(yscrollcommand=scrollbar.set) # 布局 self.user_tree.pack(side='left', fill='both', expand=True) scrollbar.pack(side='right', fill='y') # 绑定双击事件 self.user_tree.bind('<Double-1>', self.on_user_tree_double_click) def on_tree_double_click(self, event): """处理表格双击事件""" try: item = self.data_tree.selection()[0] values = self.data_tree.item(item)['values'] if not values: return video_url = values[5] # 获取视频链接 if video_url: # 确保URL格式正确 if not video_url.startswith('http'): if video_url.startswith('//'): video_url = 'https:' + video_url elif video_url.startswith('/'): video_url = 'https://www.douyin.com' + video_url else: video_url = 'https://www.douyin.com/' + video_url # 使用默认浏览器打开链接 import webbrowser webbrowser.open(video_url) except Exception as e: print(f"打开视频链接错误: {str(e)}") messagebox.showerror("错误", "无法打开视频链接") def on_user_tree_double_click(self, event): """处理用户表格双击事件""" try: item = self.user_tree.selection()[0] values = self.user_tree.item(item)['values'] if not values: return user_url = values[6] # 获取用户主页链接 if user_url: # 确保URL格式正确 if not user_url.startswith('http'): if user_url.startswith('//'): user_url = 'https:' + user_url elif user_url.startswith('/'): user_url = 'https://www.douyin.com' + user_url else: user_url = 'https://www.douyin.com/' + user_url # 使用默认浏览器打开链接 import webbrowser webbrowser.open(user_url) except Exception as e: print(f"打开用户主页链接错误: {str(e)}") messagebox.showerror("错误", "无法打开用户主页链接") def create_analysis_tab(self): """创建数据分析标签页""" analysis_frame = ttk.Frame(self.notebook) self.notebook.add(analysis_frame, text='数据分析') # 创建分析结果文本框 self.analysis_text = tk.Text(analysis_frame, height=20, width=60) self.analysis_text.pack(pady=10, padx=10, fill='both', expand=True) # 创建按钮框架 button_frame = ttk.Frame(analysis_frame) button_frame.pack(pady=5) # 添加分析按钮 ttk.Button(button_frame, text="互动数据分析", command=self.analyze_interaction_data).pack(side='left', padx=5) ttk.Button(button_frame, text="内容长度分析", command=self.analyze_content_length).pack(side='left', padx=5) ttk.Button(button_frame, text="高频词汇分析", command=self.analyze_keywords).pack(side='left', padx=5) ttk.Button(button_frame, text="清空分析结果", command=lambda: self.analysis_text.delete(1.0, tk.END)).pack(side='left', padx=5) def start_search_collection(self): """开始搜索采集""" if self.is_running: messagebox.showwarning("警告", "采集正在进行中!") return self.is_running = True threading.Thread(target=self.scroll_and_collect_search).start() def scroll_and_collect_search(self): """滚动页面并收集搜索结果数据""" driver = None try: # 配置Chrome选项 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-dev-shm-usage') chrome_options.add_argument('--disable-extensions') chrome_options.add_argument('--disable-logging') chrome_options.add_argument('--log-level=3') # 启动浏览器 driver = webdriver.Chrome(options=chrome_options) # 构建搜索URL keyword = self.search_keyword.get().strip() if not keyword: messagebox.showwarning("警告", "请输入搜索关键词!") return search_type = self.search_type.get() search_url = f"https://www.douyin.com/search/{quote(keyword)}?source=normal_search&type={search_type}" print(f"访问搜索URL: {search_url}") # 访问页面 driver.get(search_url) driver.maximize_window() # 等待页面加载 try: if search_type == 'user': # 等待用户列表加载 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, '#search-content-area')) ) # 额外等待确保内容完全加载 time.sleep(5) # 增加等待时间 else: # 等待视频列表加载 WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, 'li.SwZLHMKk')) ) except Exception as e: print(f"等待页面加载超时: {str(e)}") time.sleep(3) # 额外等待时间 # 获取滚动次数和延迟 scroll_times = int(self.scroll_count.get()) delay = float(self.delay.get()) # 开始滚动和采集 last_height = driver.execute_script("return document.body.scrollHeight") for i in range(scroll_times): if not self.is_running: break try: # 滚动页面 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(delay) # 检查是否到达底部 new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: print("已到达页面底部") break last_height = new_height # 获取页面源码并解析 page_source = driver.page_source soup = BeautifulSoup(page_source, 'html.parser') # 根据搜索类型选择不同的提取方法 if search_type == 'user': new_data = self.extract_user_data(soup) else: container = soup.select_one('[data-e2e="scroll-list"]') if container: new_data = self.extract_video_items(container) else: print("未找到视频列表容器") continue print(f"本次滚动找到 {len(new_data)} 条新数据") # 添加新数据(去重) for data in new_data: if data not in self.collected_data: self.collected_data.append(data) print(f"当前总共采集 {len(self.collected_data)} 条数据") # 更新数据显示 self.root.after(0, self.update_data_display) # 使用after确保在主线程中更新UI # 更新状态 self.status_label.config(text=f"正在滚动... ({i+1}/{scroll_times})") self.progress['value'] = (i + 1) / scroll_times * 100 except Exception as e: print(f"滚动错误: {str(e)}") continue print("搜索结果采集完成") self.status_label.config(text=f"采集完成,共获取{len(self.collected_data)}条数据") except Exception as e: print(f"搜索采集过程出错: {str(e)}") messagebox.showerror("错误", f"采集过程出错: {str(e)}") finally: self.is_running = False if driver: driver.quit() def extract_video_data(self, html): """提取数据""" if self.search_type.get() == 'user': return self.extract_user_data(html) else: return self.extract_video_items(html) def extract_user_data(self, html): """提取用户数据""" print("开始提取用户数据...") # 使用正确的选择器定位用户列表 user_items = html.select("div.search-result-card > a.hY8lWHgA.poLTDMYS") # 更新选择器 print(f"找到 {len(user_items)} 个用户项") user_data = [] for item in user_items: try: # 获取用户链接 user_link = item.get('href', '') # 获取标题 title_elem = item.select_one('div.XQwChAbX p.v9LWb7QE span span span span span') title = title_elem.get_text(strip=True) if title_elem else '' # 获取头像URL avatar_elem = item.select_one('img.RlLOO79h') avatar_url = avatar_elem.get('src', '') if avatar_elem else '' # 获取统计数据 stats_div = item.select_one('div.jjebLXt0') douyin_id = '' likes = '0' followers = '0' if stats_div: spans = stats_div.select('span') for span in spans: text = span.get_text(strip=True) print(f"处理span文本: {text}") # 调试输出 if '抖音号:' in text or '抖音号:' in text: id_span = span.select_one('span') if id_span: douyin_id = id_span.get_text(strip=True) elif '获赞' in text: likes = text.replace('获赞', '').strip() elif '粉丝' in text: followers = text.replace('粉丝', '').strip() # 获取简介 desc_elem = item.select_one('p.Kdb5Km3i span span span span span') description = desc_elem.get_text(strip=True) if desc_elem else '' # 构建数据 data = { 'title': title, 'douyin_id': douyin_id, 'likes': likes, 'followers': followers, 'description': description, 'avatar_url': avatar_url, 'user_link': user_link } # 清理数据 data = {k: self.clean_text(str(v)) for k, v in data.items()} # 格式化数字 data['likes'] = self.format_number(data['likes']) data['followers'] = self.format_number(data['followers']) # 处理用户链接 if data['user_link'] and not data['user_link'].startswith('http'): data['user_link'] = 'https://www.douyin.com' + data['user_link'] # 打印调试信息 print("\n提取到的数据:") for key, value in data.items(): print(f"{key}: {value}") # 只要有标题就添加 if data['title']: if data not in user_data: # 确保不重复添加 user_data.append(data) print(f"成功提取用户数据: {data['title']}") except Exception as e: print(f"提取单个用户数据错误: {str(e)}") traceback.print_exc() # 打印完整的错误堆栈 continue print(f"总共提取到 {len(user_data)} 条用户数据") return user_data def _extract_basic_info(self, item): """提取基本信息""" # 获取用户链接 user_link = item.select_one('a.uz1VJwFY') # 使用确切的类名 # 获取标题 title = "" title_elem = item.select_one('p.ZMZLqKYm span') # 使用确切的类名和结构 if title_elem: title = title_elem.get_text(strip=True) # 获取头像URL avatar_elem = item.select_one('img.fiWP27dC') avatar_url = avatar_elem.get('src', '') if avatar_elem else '' return { 'title': title, 'douyin_id': '', 'likes': '', 'followers': '', 'description': '', 'avatar_url': avatar_url, 'user_link': user_link.get('href', '') if user_link else '' } def _extract_stats_info(self, item, data): """提取统计信息""" stats_div = item.select_one('div.Y6iuJGlc') # 使用确切的类名 if stats_div: spans = stats_div.select('span') spans_text = [span.get_text(strip=True) for span in spans] print(f"找到的span文本: {spans_text}") # 调试输出 for text in spans_text: if '抖音号:' in text or '抖音号:' in text: # 获取嵌套的span中的抖音号 nested_span = stats_div.select_one('span > span') if nested_span: data['douyin_id'] = nested_span.get_text(strip=True) elif '获赞' in text: data['likes'] = text.replace('获赞', '').strip() elif '粉丝' in text: data['followers'] = text.replace('粉丝', '').strip() def _extract_description(self, item, data): """提取用户简介""" desc_elem = item.select_one('p.NYqiIDUo span') # 使用确切的类名和结构 if desc_elem: # 获取纯文本内容,去除表情图片 text_nodes = [node for node in desc_elem.stripped_strings] data['description'] = ' '.join(text_nodes) def _clean_and_format_data(self, data): """清理和格式化数据""" # 清理文本数据 for key in data: if isinstance(data[key], str): data[key] = self.clean_text(data[key]) # 格式化数字 data['likes'] = self.format_number(data['likes']) data['followers'] = self.format_number(data['followers']) # 处理用户链接 if data['user_link']: link = data['user_link'] # 移除查询参数 if '?' in link: link = link.split('?')[0] # 确保正确的格式 if link.startswith('//'): link = 'https:' + link elif not link.startswith('http'): # 移除可能的重复路径 link = link.replace('www.douyin.com/', '') link = link.replace('//', '/') if not link.startswith('/'): link = '/' + link link = 'https://www.douyin.com' + link print(f"原始链接: {data['user_link']}") # 调试输出 print(f"处理后链接: {link}") # 调试输出 data['user_link'] = link def _print_debug_info(self, data): """打印调试信息""" print("\n提取到的数据:") print(f"标题: {data['title']}") print(f"抖音号: {data['douyin_id']}") print(f"获赞: {data['likes']}") print(f"粉丝: {data['followers']}") print(f"简介: {data['description'][:50]}...") print(f"链接: {data['user_link']}") def extract_video_items(self, html): """提取视频数据(原有代码)""" video_items = html.select("li.SwZLHMKk") video_data = [] for item in video_items: try: # 获取视频链接 video_link = item.select_one('a.hY8lWHgA') if not video_link: continue # 构建数据 data = { 'video_url': video_link['href'].strip(), 'cover_image': item.select_one('img')['src'].strip() if item.select_one('img') else '', 'title': item.select_one('div.VDYK8Xd7').text.strip() if item.select_one('div.VDYK8Xd7') else '无标题', 'author': item.select_one('span.MZNczJmS').text.strip() if item.select_one('span.MZNczJmS') else '未知作者', 'publish_time': item.select_one('span.faDtinfi').text.strip() if item.select_one('span.faDtinfi') else '', 'likes': item.select_one('span.cIiU4Muu').text.strip() if item.select_one('span.cIiU4Muu') else '0' } # 清理数据 data = {k: self.clean_text(str(v)) for k, v in data.items()} # 验证数据完整性 if all(data.values()): video_data.append(data) else: print(f"跳过不完整数据: {data}") except Exception as e: print(f"提取单个视频数据错误: {str(e)}") continue return video_data def update_data_display(self): """更新数据显示""" try: search_type = self.search_type.get() print(f"更新数据显示,搜索类型: {search_type}") print(f"当前数据数量: {len(self.collected_data)}") if search_type == 'user': self.notebook.select(2) # 先切换到用户数据标签页 self.root.after(100, self.update_user_display) # 延迟一小段时间后更新显示 else: self.notebook.select(1) # 切换到视频数据标签页 self.root.after(100, self.update_video_display) except Exception as e: print(f"更新数据显示错误: {str(e)}") def update_user_display(self): """更新用户数据显示""" try: # 清空现有显示 self.user_tree.delete(*self.user_tree.get_children()) # 添加新数据 for i, data in enumerate(self.collected_data): try: # 格式化简介 description = data.get('description', '') if len(description) > 50: description = description[:47] + '...' # 格式化数据 values = ( i + 1, data.get('title', ''), data.get('douyin_id', ''), self.format_number(str(data.get('likes', '0'))), self.format_number(str(data.get('followers', '0'))), description, data.get('user_link', ''), data.get('avatar_url', '') ) self.user_tree.insert('', 'end', values=values) print(f"显示用户数据: {data.get('title', '')}") except Exception as e: print(f"处理单条用户数据显示错误: {str(e)}") continue # 更新统计 self.user_stats_label.config(text=f"共采集到 {len(self.collected_data)} 位用户") print(f"更新用户统计: {len(self.collected_data)} 位用户") # 自动滚动到最新数据 if self.user_tree.get_children(): self.user_tree.see(self.user_tree.get_children()[-1]) except Exception as e: print(f"更新用户数据显示错误: {str(e)}") def update_video_display(self): """更新视频数据显示(原有的update_data_display逻辑)""" try: # 清空现有显示 self.data_tree.delete(*self.data_tree.get_children()) # 添加新数据 for i, data in enumerate(self.collected_data): try: title = data.get('title', '') if len(title) > 50: title = title[:47] + '...' values = ( i + 1, title, data.get('author', '未知作者'), data.get('publish_time', ''), self.format_number(str(data.get('likes', '0'))), data.get('video_url', '') ) self.data_tree.insert('', 'end', values=values) except Exception as e: print(f"处理单条数据显示错误: {str(e)}") continue # 更新统计 self.stats_label.config(text=f"共采集到 {len(self.collected_data)} 条数据") # 自动滚动到最新数据 if self.data_tree.get_children(): self.data_tree.see(self.data_tree.get_children()[-1]) except Exception as e: print(f"更新数据显示错误: {str(e)}") def update_data_stats(self): """更新数据统计""" try: total_count = len(self.collected_data) self.stats_label.config(text=f"共采集到 {total_count} 条数据") except Exception as e: print(f"更新统计信息错误: {str(e)}") def stop_collection(self): """停止数据采集""" if self.is_running: self.is_running = False self.status_label.config(text="已停止采集") print("采集已停止") else: print("当前没有正在进行的采集任务") def export_excel(self): """导出数据到Excel""" if not self.collected_data: messagebox.showwarning("警告", "没有数据可导出!") return try: filename = f"抖音数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx" df = pd.DataFrame(self.collected_data) df.to_excel(filename, index=False) messagebox.showinfo("成功", f"数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出Excel失败: {str(e)}") def export_json(self): """导出数据到JSON""" if not self.collected_data: messagebox.showwarning("警告", "没有数据可导出!") return try: filename = f"抖音数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump(self.collected_data, f, ensure_ascii=False, indent=2) messagebox.showinfo("成功", f"数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出JSON失败: {str(e)}") def export_user_excel(self): """导出用户数据到Excel""" if not self.collected_data or self.search_type.get() != 'user': messagebox.showwarning("警告", "没有用户数据可导出!") return try: filename = f"抖音用户数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx" df = pd.DataFrame(self.collected_data) df.to_excel(filename, index=False) messagebox.showinfo("成功", f"用户数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出Excel失败: {str(e)}") def export_user_json(self): """导出用户数据到JSON""" if not self.collected_data or self.search_type.get() != 'user': messagebox.showwarning("警告", "没有用户数据可导出!") return try: filename = f"抖音用户数据_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump(self.collected_data, f, ensure_ascii=False, indent=2) messagebox.showinfo("成功", f"用户数据已导出到: {filename}") except Exception as e: messagebox.showerror("错误", f"导出JSON失败: {str(e)}") def clean_text(self, text): """清理文本""" return text.replace('\n', ' ').replace('\r', '').strip() def format_number(self, num_str): """格式化数字字符串""" try: num = int(num_str) if num >= 10000: return f"{num / 10000:.1f}万" return str(num) except ValueError: return num_str def analyze_interaction_data(self): """分析互动数据""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 将点赞数转换为数字 likes_data = [] for data in self.collected_data: likes = str(data['likes']) try: if '万' in likes: # 处理带"万"的数字 num = float(likes.replace('万', '')) * 10000 likes_data.append(int(num)) else: # 处理普通数字 likes_data.append(int(likes)) except (ValueError, TypeError): print(f"无法解析的点赞数: {likes}") continue # 计算统计数据 total_likes = sum(likes_data) avg_likes = total_likes / len(likes_data) if likes_data else 0 max_likes = max(likes_data) if likes_data else 0 # 生成报告 report = "===== 互动数据分析报告 =====\n\n" report += f"总视频数: {len(self.collected_data)}\n" report += f"总点赞数: {self.format_large_number(total_likes)}\n" report += f"平均点赞数: {self.format_large_number(int(avg_likes))}\n" report += f"最高点赞数: {self.format_large_number(max_likes)}\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: print(f"互动数据分析错误: {str(e)}") messagebox.showerror("错误", f"分析失败: {str(e)}") def format_large_number(self, num): """格式化大数字显示""" if num >= 10000: return f"{num/10000:.1f}万" return str(num) def analyze_content_length(self): """分析内容长度""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 计算标题长度 title_lengths = [len(data['title']) for data in self.collected_data] # 计算统计数据 avg_length = sum(title_lengths) / len(title_lengths) max_length = max(title_lengths) min_length = min(title_lengths) # 生成报告 report = "===== 内容长度分析报告 =====\n\n" report += f"平均标题长度: {avg_length:.1f}字\n" report += f"最长标题: {max_length}字\n" report += f"最短标题: {min_length}字\n\n" # 添加长度分布统计 length_ranges = [(0, 10), (11, 20), (21, 30), (31, 50), (51, 100), (101, float('inf'))] report += "标题长度分布:\n" for start, end in length_ranges: count = sum(1 for length in title_lengths if start <= length <= end) range_text = f"{start}-{end}字" if end != float('inf') else f"{start}字以上" percentage = (count / len(title_lengths)) * 100 report += f"{range_text}: {count}个 ({percentage:.1f}%)\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: messagebox.showerror("错误", f"分析失败: {str(e)}") def analyze_keywords(self): """分析标题中的高频词汇""" if not self.collected_data: messagebox.showwarning("警告", "没有可分析的数据!") return try: # 合并所有标题文本 all_titles = ' '.join(data['title'] for data in self.collected_data) # 设置停用词 stop_words = { '的', '了', '是', '在', '我', '有', '和', '就', '都', '而', '及', '与', '着', '或', '等', '为', '一个', '没有', '这个', '那个', '但是', '而且', '只是', '不过', '这样', '一样', '一直', '一些', '这', '那', '也', '你', '我们', '他们', '它们', '把', '被', '让', '向', '往', '但', '去', '又', '能', '好', '给', '到', '看', '想', '要', '会', '多', '能', '这些', '那些', '什么', '怎么', '如何', '为什么', '可以', '因为', '所以', '应该', '可能', '应该' } # 使用jieba进行分词 words = [] for word in jieba.cut(all_titles): if len(word) > 1 and word not in stop_words: # 过滤单字词和停用词 words.append(word) # 统计词频 word_counts = Counter(words) # 生成报告 report = "===== 高频词汇分析报告 =====\n\n" report += f"总标题数: {len(self.collected_data)}\n" report += f"总词汇量: {len(words)}\n" report += f"不同词汇数: {len(word_counts)}\n\n" # 显示高频词汇(TOP 100) report += "高频词汇 TOP 100:\n" report += "-" * 40 + "\n" report += "排名\t词汇\t\t出现次数\t频率\n" report += "-" * 40 + "\n" for rank, (word, count) in enumerate(word_counts.most_common(100), 1): frequency = (count / len(words)) * 100 report += f"{rank}\t{word}\t\t{count}\t\t{frequency:.2f}%\n" # 显示分析结果 self.analysis_text.delete(1.0, tk.END) self.analysis_text.insert(tk.END, report) except Exception as e: print(f"高频词汇分析错误: {str(e)}") messagebox.showerror("错误", f"分析失败: {str(e)}") def treeview_sort_column(self, tree, col, reverse): """列排序函数""" # 获取所有项目 l = [(tree.set(k, col), k) for k in tree.get_children('')] try: # 尝试将数值型数据转换为数字进行排序 if col in ['序号', '获赞数', '粉丝数', '点赞数']: # 处理带"万"的数字 def convert_number(x): try: if '万' in x[0]: return float(x[0].replace('万', '')) * 10000 return float(x[0]) except ValueError: return 0 l.sort(key=convert_number, reverse=reverse) else: # 字符串排序 l.sort(reverse=reverse) except Exception as e: print(f"排序错误: {str(e)}") # 如果转换失败,按字符串排序 l.sort(reverse=reverse) # 重新排列项目 for index, (val, k) in enumerate(l): tree.move(k, '', index) # 更新序号 tree.set(k, '序号', str(index + 1)) # 切换排序方向 tree.heading(col, command=lambda: self.treeview_sort_column(tree, col, not reverse)) def create_help_tab(self): """创建帮助标签页""" help_frame = ttk.Frame(self.notebook) self.notebook.add(help_frame, text='使用帮助') # 创建帮助文本框 help_text = tk.Text(help_frame, wrap=tk.WORD, padx=10, pady=10) help_text.pack(fill='both', expand=True) # 添加滚动条 scrollbar = ttk.Scrollbar(help_frame, orient='vertical', command=help_text.yview) scrollbar.pack(side='right', fill='y') help_text.configure(yscrollcommand=scrollbar.set) # 帮助内容 help_content = """ 抖音作品分析工具使用指南 ==================== 1. 数据采集 ----------------- • 支持两种采集方式: - 直接输入抖音链接 - 关键词搜索采集 • 关键词搜索支持以下类型: - 视频搜索 - 用户搜索 - 音乐搜索 - 话题搜索 • 采集参数说明: - 滚动次数:决定采集数据量的多少 - 延迟(秒):每次滚动的等待时间,建议2-3秒 • 使用技巧: - 采集时可随时点击"停止采集" - 建议设置适当的延迟避免被限制 - 数据采集过程中请勿关闭浏览器窗口 2. 数据查看 ----------------- • 视频数据: - 包含标题、作者、发布时间等信息 - 双击可直接打开视频链接 - 支持按列排序 - 可导出为Excel或JSON格式 • 用户数据: - 显示用户名、抖音号、粉丝数等信息 - 双击可打开用户主页 - 支持数据排序 - 可单独导出用户数据 3. 数据分析 ----------------- • 互动数据分析: - 统计总点赞数、平均点赞等指标 - 展示互动数据分布情况 • 内容长度分析: - 分析标题长度分布 - 显示最长/最短标题统计 • 高频词汇分析: - 提取标题中的关键词 - 展示TOP100高频词汇 - 计算词频占比 4. 常见问题 ----------------- Q: 为什么采集速度较慢? A: 为了避免被反爬虫机制拦截,程序设置了延迟机制。 Q: 如何提高采集成功率? A: 建议: - 设置适当的延迟时间(2-3秒) - 避免过于频繁的采集 - 确保网络连接稳定 Q: 数据导出格式说明? A: 支持两种格式: - Excel格式:适合数据分析和处理 - JSON格式:适合数据备份和程序读取 Q: 如何处理采集失败? A: 可以: - 检查网络连接 - 增加延迟时间 - 减少单次采集数量 - 更换搜索关键词 5. 注意事项 ----------------- • 合理使用: - 遵守抖音平台规则 - 避免频繁、大量采集 - 合理设置采集参数 • 数据安全: - 及时导出重要数据 - 定期备份采集结果 • 使用建议: - 建议使用稳定的网络连接 - 采集时避免其他浏览器操作 - 定期清理浏览器缓存 如需更多帮助,请参考项目文档或联系开发者。 """ # 插入帮助内容 help_text.insert('1.0', help_content) help_text.config(state='disabled') # 设置为只读 if __name__ == "__main__": root = tk.Tk() app = DouyinAnalyzer(root) root.mainloop() #您下载的资源来自www.fulicode.cn三、下载指南 123云盘下载 抖音数据采集分析工具.zip 下载地址:https://www.123684.com/s/rCKrjv-Vpb8d? 提取码:vq7x无论你是经验丰富的专业开发者,能够熟练地对代码进行二次开发与定制;还是对抖音数据满怀热忱、刚刚踏入数据领域的爱好者,渴望通过数据了解抖音世界的奥秘,都能毫无门槛地获取这份宝贵的资源。我们衷心希望这款工具能够在你的创作与分析旅程中发挥重要作用,帮助你在抖音平台的创作之路上更加得心应手,在市场分析领域取得更优异的成果,开启属于自己的数据洞察新征程。
-
彩虹外链网盘源码 - PHP 网盘与外链分享程序,功能强大且安全可靠! 彩虹外链网盘源码:功能、安装与使用全解析 在互联网的世界里,拥有一款高效实用的网盘源码至关重要。今天要为大家详细介绍的是彩虹外链网盘界面 UI 美化版源码,它凭借丰富多样的功能和简洁美观的设计,成为众多用户的心仪之选。 截图 截图 - 首页图片 上传图片 一、功能亮点 强大的文件上传与外链生成功能 这款源码基于 PHP 开发,支持所有常见格式文件的上传。无论是日常办公的.doc、.xls 等文档,还是.jpg、.png 等格式的图片,亦或是.mp3、.mp4 等音频视频文件,都能顺利上传至网盘。 它能够生成文件外链、图片外链、音乐视频外链,并且在生成外链的同时自动生成相应的 UBB 代码和 HTML 代码。这使得用户在不同的网络平台(如论坛、博客、网站等)分享文件变得极为便捷。例如,在一个摄影爱好者论坛中,用户可以上传自己的摄影作品图片到彩虹外链网盘,然后将生成的图片外链和相应代码嵌入帖子中,与其他爱好者分享高清作品,无需担心图片占用论坛空间或因格式问题无法展示。 丰富的媒体预览功能 彩虹外链网盘不仅是一个存储工具,还是一个多功能的媒体平台。它支持文本、图片、音乐、视频在线预览。对于文本文件,用户无需下载即可直接查看内容,方便快速查阅资料。在查看图片时,其高分辨率的预览效果能够清晰展示图片细节,满足设计师、摄影师等对图片质量的要求。音乐和视频的在线预览功能则让用户可以在不占用本地存储空间的情况下,先试听或试看,确定是否需要下载,节省了大量时间和空间。 云存储对接与安全保障 新版本的源码支持对接阿里云 OSS、腾讯云 COS、华为云 OBS、又拍云、七牛云等云存储。这一功能为用户提供了更强大的存储扩展能力和数据安全保障。企业用户可以利用这些云存储服务的高可靠性和大容量特点,存储大量的业务文件,如公司的宣传视频、产品设计图等。同时,通过与云存储的对接,数据的备份和恢复也更加便捷,降低了数据丢失的风险。 增加的图片违规检测功能进一步确保了平台的合法性和安全性。它可以自动识别并过滤掉含有淫秽、侵权等违法内容的图片,为用户营造一个健康、合法的文件存储和分享环境。 便捷的文件管理与共享功能 适合小文件快速共享,用户可以轻松设置文件访问密码,增强文件的保密性。例如,教师可以将教学资料上传到网盘并设置密码,只分享给班级的学生,确保资料的安全性和针对性。 对于 doc 等文档和图片,支持在线预览,音频可以在线播放,也适合做图床,并且支持在线下载。这一系列功能使得用户在不同的使用场景下都能快速获取和处理文件,提高了工作和学习效率。 二、安装步骤 准备工作 确保您的服务器环境支持 PHP 运行,并且已经安装了必要的数据库(如 MySQL)。 上传与解压 将下载的彩虹外链网盘源码文件上传至您的服务器指定目录。然后使用解压缩工具对文件进行解压操作,确保所有文件都完整解压到相应目录。 彩虹外链网盘界面UI美化版超级简洁好看.zip 下载地址:https://www.123684.com/s/rCKrjv-Dpb8d 提取码: 数据库配置 找到解压后的文件中的 config.php 文件,使用文本编辑器打开它。在文件中,您需要修改数据库信息,包括数据库主机地址(通常为 localhost,但如果您的数据库在远程服务器上,则需要填写相应的 IP 地址)、数据库用户名、数据库密码以及数据库名称。确保这些信息与您的服务器数据库设置一致,否则网盘将无法正常连接数据库。 导入数据库 上传文件内的数据库.sql 文件到您的数据库管理工具中,并执行导入操作。这将创建彩虹外链网盘所需的数据库表和初始数据。 登录后台 完成上述步骤后,在浏览器中输入访问后台地址/admin,使用默认账号密码 admin/123456 登录。登录成功后,您可以根据自己的需求对网盘进行进一步的设置和管理,如设置网站名称、添加友情链接等。 总之,彩虹外链网盘界面 UI 美化版源码为用户提供了一个功能强大、操作便捷且安全可靠的文件存储和分享解决方案。无论是个人用户用于存储和分享个人资料、作品,还是企业用户用于团队协作和文件管理,都具有很高的实用价值。按照上述安装步骤,您可以快速搭建起属于自己的网盘平台,享受其带来的便利。
-
免费开源 Jasmine Typecho 博客主题:简约美观与强大功能的完美结合,不容错过! 免费开源!Jasmine Typecho博客主题惊艳登场,你不能错过! 前言 在浩瀚的博客主题海洋中,总有那么一些璀璨的明珠等待我们去发现。今天,要向大家隆重推荐一款令人惊艳的Typecho博客主题——Jasmine!它就像一股清新的风,为你的博客世界带来简约、美观与强大功能的完美融合。主题预览 主题预览图片 源码介绍 一、令人心动的视觉盛宴 Jasmine主题以其独特的设计理念,将白、灰、黑三种经典配色运用得炉火纯青,打造出一场视觉的奢华盛宴。白色,如同初升的朝阳,洒下纯净而明亮的光辉,赋予整个博客页面开阔无垠的感觉,让每一个字符都仿佛在这明亮的舞台上翩翩起舞;灰色,恰似静谧的月光,沉稳而内敛,恰到好处地在白色与黑色之间穿梭,为画面增添了层次感和立体感,使元素之间的过渡如丝般顺滑;黑色,则宛如深邃的夜空,神秘而庄重,在关键之处点缀,吸引着读者的目光,仿佛夜空中闪烁的璀璨星辰。这种极简主义的配色方案,共同勾勒出一个简洁精致、美轮美奂的博客空间,让读者在踏入的瞬间,便沉浸于这高雅的氛围之中。 不仅如此,Jasmine主题的响应式设计更是一绝!无论是在宽敞的电脑显示屏前,还是在小巧便携的移动设备上,它都能如灵动的舞者般,自适应屏幕的每一寸空间。在电脑端,页面布局大气磅礴,内容排版井然有序,图片与文字相互辉映,每一处细节都彰显着精致;而在移动端,简洁流畅的界面仿佛是为你的手指量身定制,轻轻滑动,即可畅览博客的精彩世界,随时随地享受阅读的畅快淋漓。无论你身处何地,Jasmine主题都能确保你的博客以最完美的姿态呈现在读者眼前。 二、强大功能,一应俱全 SEO优化:让你的博客闪耀在搜索之巅 在信息如繁星般繁多的互联网宇宙中,如何让你的博客成为那颗最耀眼的星?Jasmine主题给出了完美答案——强大的SEO优化功能!它如同一位智慧的导航者,精心优化页面标题、精准定位关键词、巧妙布局文章结构与链接,让搜索引擎的“目光”轻易锁定你的博客。从此,你的精彩内容将不再被埋没,在搜索结果中名列前茅,吸引无数潜在读者踏入你的博客天地,开启知识与思想的交流之旅。 夜间模式切换:贴心呵护你的每一次阅读 当夜幕降临,柔和的光线成为阅读的最佳伴侣。Jasmine主题深知你的需求,特别配备了夜间模式切换功能。只需轻轻一点,整个博客世界便瞬间披上一层温馨的夜色。屏幕亮度恰到好处地降低,颜色对比度也调整到最适宜夜间阅读的状态,文字仿佛在这柔和的光线下轻声诉说,让你的眼睛在享受阅读乐趣的同时,得到无微不至的呵护。无论是在宁静的夜晚,伴着一杯香浓的咖啡沉浸于文字的海洋,还是在昏暗的灯光下,寻找心灵的慰藉,Jasmine的夜间模式都将为你营造出最舒适的阅读环境。 置顶文章显示:重要信息,始终在聚光灯下 在博客的舞台上,有些文章是当之无愧的主角,需要时刻站在聚光灯下。Jasmine主题的置顶文章显示功能,让你轻松掌控这一切。只需简单操作,你就能将那些重要通知、热门话题或必读佳作置顶,使其在博客首页或文章列表中以最醒目的方式呈现。从此,关键信息再也不会被海量文章淹没,读者一进入你的博客,便能迅速捕捉到这些精华内容,不错过任何精彩瞬间。 评论功能支持:搭建互动交流的桥梁 博客,不仅仅是一个人的舞台,更是一个充满活力的社区。Jasmine主题深知互动的力量,为你搭建起一座坚固的评论功能桥梁。读者们可以在这里畅所欲言,分享自己的观点、感悟和建议,与你以及其他读者展开深入的思想碰撞。每一条评论都是一颗思想的火花,在互动中,博客的活力被充分激发,社区氛围愈发浓厚。你将从中汲取宝贵的反馈,获取源源不断的灵感,与读者共同成长,共同打造一个充满温度与智慧的博客家园。 QQ头像显示:让评论区充满个性魅力 为了让评论区更加生动有趣,Jasmine主题别出心裁地引入了QQ头像显示功能。当读者留下评论时,他们独特的QQ头像将一同出现,仿佛为每一条评论都赋予了鲜活的生命。这些头像就像一面面个性的旗帜,在评论区飘扬,让你在阅读评论时,能更直观地感受到背后每一个独特的个体。每一个头像都承载着一段故事,它们的存在让交流不再枯燥,而是充满了亲切与趣味,仿佛一场盛大的线上聚会,大家在这里分享、交流、欢笑。 代码高亮:技术分享的得力助手 对于技术爱好者和开发者来说,Jasmine主题的代码高亮功能简直是如虎添翼。在分享编程经验、展示代码片段或讲解技术原理时,它能将代码以最清晰、最易读的方式呈现。不同的代码元素被赋予不同的颜色和字体样式,代码结构一目了然,语法错误无处遁形。就像一位专业的导师,在你探索技术的道路上,为你点亮一盏明灯,让复杂的代码世界变得简单易懂,大大提升了技术类文章的阅读体验和知识传递效率。 随机文章跳转:开启探索未知的惊喜之旅 有时候,阅读需要一点惊喜与冒险。Jasmine主题的随机文章跳转功能,就像是一把神秘的钥匙,带你打开一扇扇未知的知识大门。当你点击随机文章按钮,系统将带你踏上一段充满惊喜的旅程,随机推荐一篇博客中的文章。也许你会偶然发现一篇深入剖析你一直感兴趣话题的宝藏文章,也许你会踏入一个全新的知识领域,结识从未想象过的奇妙思想。每一次点击,都是一次探索未知的冒险,让你的阅读体验充满无限可能。 文章缩略图设置:吸引目光的视觉魔法 在信息飞速传播的时代,如何让你的文章在众多竞争者中脱颖而出?Jasmine主题的文章缩略图设置功能就是你的秘密武器。为每篇文章精心挑选一张吸引人的缩略图,就像是为它穿上了一件华丽的外衣。在文章列表中,这些缩略图将以直观、生动的形象吸引读者的目光,如同无声的推销员,向读者传达文章的核心魅力。无论是一幅美轮美奂的风景照,还是一张引人深思的漫画,亦或是一张专业严谨的图表,都能在瞬间抓住读者的眼球,激发他们的阅读兴趣,让你的文章从众多文字中脱颖而出,成为读者无法抗拒的阅读诱惑。 外观设置备份:数据安全的坚实护盾 在打造个性化博客的过程中,你花费了无数心血调整主题的外观设置。Jasmine主题深知你的努力来之不易,因此为你配备了外观设置备份功能。在你大胆尝试新的设置或进行修改之前,只需轻轻一点,就能为当前的外观设置创建一个安全备份。这就像为你的博客设置了一道坚固的护盾,即使在后续操作中出现意外,如设置错乱或数据丢失,你也能随时恢复到之前的完美状态,确保所有的努力和创意都不会付诸东流。从此,你可以毫无后顾之忧地探索和定制主题的外观,尽情释放你的创意才华。 主题更新检测:与时代同步,永不止步 互联网的浪潮永不停歇,技术在不断进步,Jasmine主题也在与时俱进。它具备强大的主题更新检测功能,时刻关注着技术的前沿动态。一旦有新的版本发布,它将第一时间通知你,确保你的博客始终运行在最佳状态。这些更新可能包含新功能的加入,让你的博客更加丰富多彩;性能优化,使浏览速度如闪电般迅速;安全漏洞修复,为你的博客筑牢安全防线。选择Jasmine主题,就等于选择了与时代同步,让你的博客始终站在潮流的前沿,为读者提供最优质、最先进的阅读体验。 三、免费开源,共享创意 Jasmine主题不仅以其卓越的设计和强大的功能令人倾心,更重要的是,它是免费开源的!这意味着你无需花费一分钱,就能将这款顶级主题应用于你的博客,开启一段精彩的创作之旅。同时,它遵循GPL V3.0协议开源,鼓励用户在尊重知识产权的前提下,对主题进行二次开发和个性化定制。你可以根据自己的独特创意和需求,对Jasmine主题进行修改、扩展和优化,让它真正成为你博客的专属标志。无论是技术高手想要深入挖掘主题的潜力,还是创意达人渴望打造独一无二的视觉风格,Jasmine主题都为你提供了广阔的创作空间。 四、超高人气,品质见证 自发布以来,Jasmine主题在短短20天内就赢得了54个stars的青睐,这一成绩无疑是对其品质的最佳证明。众多博主纷纷选择Jasmine,用它来装扮自己的博客天地,分享自己的故事与见解。如果你也想成为这个精彩社区的一员,亲身体验Jasmine主题的魅力,那就赶紧行动吧! 下载 123云盘下载 jasmine主题 下载地址:https://www.123684.com/s/rCKrjv-4xb8d? 提取码:FLYM
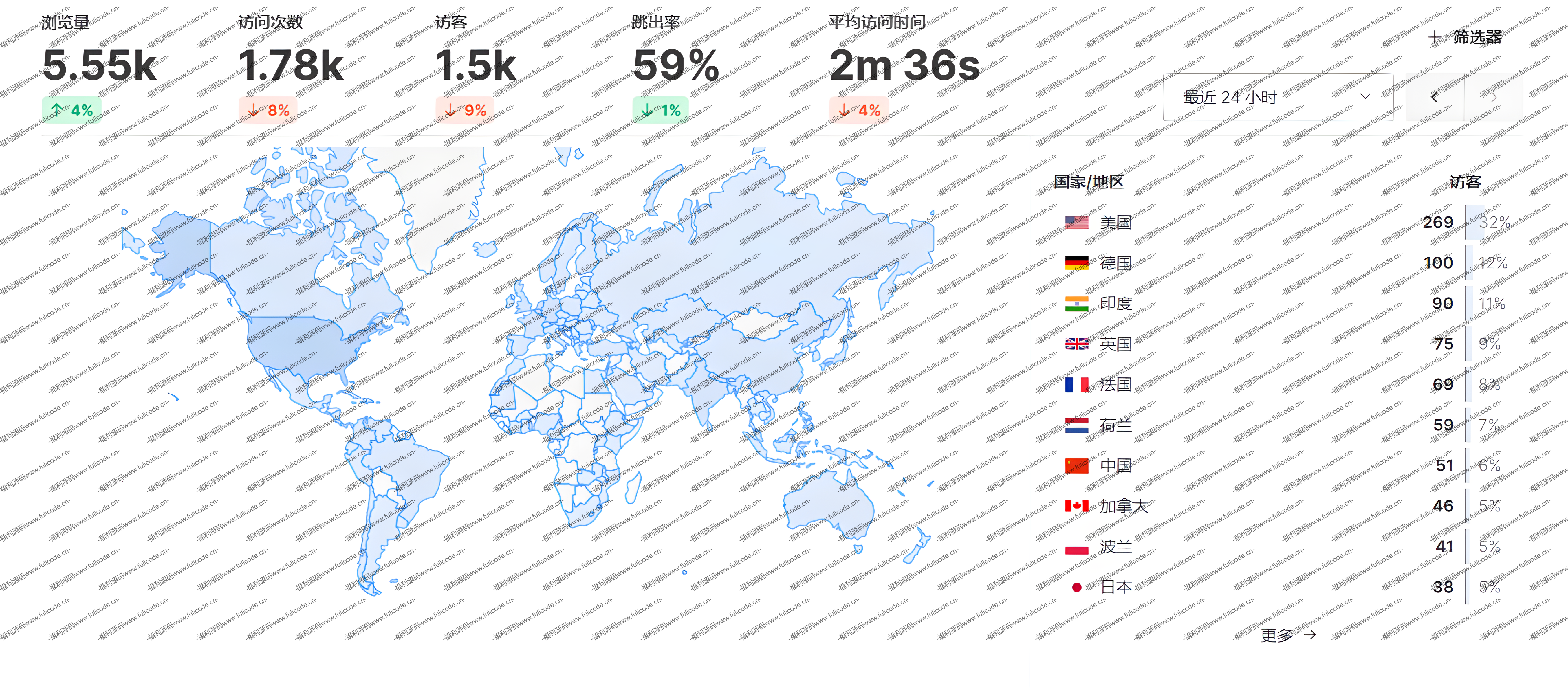



![[亲测]鲸发卡 v11.71 企业级发卡系统源码下载](https://file.fulicode.cn/view.php/bc5a76d462c8243c9c9a25219312123f.jpg)